안녕하세요 Acorn입니다.
오늘 리뷰할 논문은 The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits입니다.
Geeknews에서도 소개되었고, 유튜버 조코딩님께서도 라이브에서 언급했던 만큼 제법 이슈가 있고, 엣지 디바이스에서 LLM을 이용하여 서비스를 이용하고자 하는 사람들에게는 유용한 내용인 것 같아 소개해봅니다.
링크
https://news.hada.io/topic?id=13573
1비트 LLM 시대: 비용 효율적인 컴퓨팅을 위한 삼진 파라미터 | GeekNews
1비트 대형 언어 모델의 시대: 모든 대형 언어 모델은 1.58비트에 있다최근 연구인 BitNet은 1비트 대형 언어 모델(LLMs)의 새로운 시대를 열고 있음.이 연구에서는 모든 단일 매개변수(또는 가중치)
news.hada.io
https://arxiv.org/abs/2402.17764
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It ma
arxiv.org
https://github.com/Entropy-xcy/bitnet158
GitHub - Entropy-xcy/bitnet158
Contribute to Entropy-xcy/bitnet158 development by creating an account on GitHub.
github.com
배경색
빨간 배경 : 나의 의견
파란 배경 : 중요한 내용
서론
인공지능의 심장부라 할 수 있는 대규모 언어 모델들은 그 성능의 향상과 더불어 지속적으로 커지는 하드웨어 요구 사항에 대한 해답을 찾는 과정에 있습니다. 최신 연구들은 모델의 가중치를 정교하게 양자화하여 메모리 사용량을 줄이는 동시에 계산 효율성을 높이는 방향으로 진전되고 있습니다. 기존에는 16비트를 기준으로 사용되던 가중치들을 4비트, 심지어는 더 낮은 비트 수준으로 축소하는 시도가 있었습니다. 그러나 이 논문에서는 더욱 급진적인 접근을 시도합니다. 바로, 가중치를 단 3가지 값인 {-1, 0, 1}으로 제한하는 삼진법 양자화 기법을 제안함으로써, 모델의 성능을 유지하며 연산 속도를 향상시키고, 에너지 소비를 현저히 줄이는 방법에 대해 소개합니다.
이는 특히 에너지 소비가 중대한 이슈가 되고 있는 현대 사회에서 인공지능 연구와 응용에 있어 한 걸음 더 나아가는 발판을 제공합니다. 본 논문은 이러한 새로운 양자화 방법이 어떻게 대규모 언어 모델의 연산 부담을 경감시키고, 성능은 유지하면서 에너지 효율성을 극대화할 수 있는지에 대한 근거를 제시합니다.
이 블로그 포스팅을 통해, 우리는 해당 연구가 제안하는 삼진법 양자화가 어떻게 대규모 언어 모델의 새로운 지평을 열었는지, 그리고 이러한 변화가 언어 모델의 미래, 특히 모바일 및 엣지 컴퓨팅과 같은 자원이 제한된 환경에서의 AI 응용에 어떤 영향을 미칠지에 대해 자세히 살펴볼 것입니다.
본론
가중치를 어째서 -1,0,1 3가지만 사용하고, 1.58bit만 사용하는지에 대한 아이디어가 담긴 그림입니다. 이 논문의 서론만 읽었을때는 잘 이해가 안갔지만 이 그림을 보면 논문의 저자가 무슨 이야기를 하고 싶은지 금방 알 수 있습니다.

완전 양자화인 0과 1이 아닌 어째서 -1,0,1로 나누는 지에 대한 직관적인 이해가 담긴 부분입니다. 기존 양자화의 경우에는 가중치가 담긴 W에서 벡터화된 입력값 x가 들어와 W1x1 + W2x2 ... 와 같은 연산을 하였다면, 모든 가중치가 -1, 0 1이기에 덧셈 뺄셈만 하여 연산을 줄이는 것입니다.

가중치를 {-1,0,1}로 변환하기 위한 수식입니다. 쉽게 생각하면 반올림해서 가장 가까운 정수로 치환한다는 내용입니다.
논문의 서론에 따르면 가중치의 표현을 극한으로 단순하게 바꾸어도 LLM의 퍼포먼스는 유지가 된다고 한다. 실제로 그런지 결과표를 확인해봅시다.


LLaMA와 BitNet b1.58의 퍼포먼스 테이블이다. 각 지표별 약간의 성능 감소는 있으나, 이 정도면 큰 차이가 안난다고 해도 무방한 것 같습니다. 특히 PPL(perplexity)가 3B모델의 경우 약간이지만 기존 LLaMA 3B 모델보다 낮은 모습까지 보이니, 적어도 LLaMA에서는 성능 개선이라고 보기는 어려우나, 성능이 유지된다 라고 보기에는 무방하다 생각합니다.

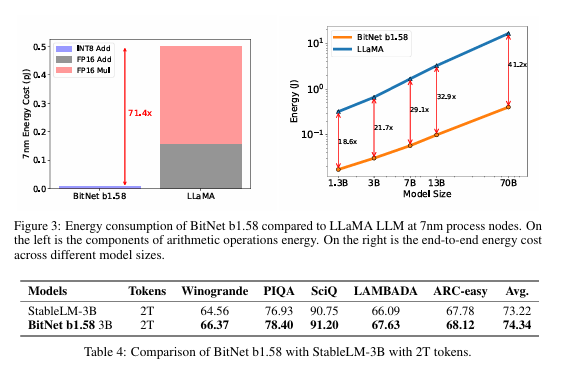
이 그림의 경우 Bitnet1.58의 하드웨어 퍼포먼스를 보여줍니다. 레이턴시나 메모리 전부 모델이 커지면 커질수록 더 큰 폭으로 자원을 절약할 수 있음을 보여줍니다. 3B모델의 경우 2.3GB정도 사용되므로 메모리가 4GB 정도 되는 디바이스라면 아슬아슬하게 작동할 것으로 보입니다. 특히 에너지 차원에서는 최대 71.4배(...대박) 을 절약한다고 하니 충격적인 퍼포먼스입니다.
요약 및 내 생각
모델의 가중치를 삼항자{-1, 0, 1}로 반올림 하여 변환하여 LLM의 퍼포먼스 유지와 함께 자원의 절약이 가능함을 시사합니다. 1비트 LLM을 통해 얻을 수 있는 이점은 모델의 크기와 복잡성이 증가함에 따라 더욱 중요해질 것이며, 이는 특히 자원이 제한된 환경에서 AI 기술을 사용하고자 하는 개발자들에게 매력적일 것이라 생각됩니다.
그래서 엣지 디바이스(온 디바이스)에서 새로운 시도를 할 수 있음을 보여주지 않을까(특히 스마트폰이나 RP5와 같은 디바이스의 경우 메모리와 발열문제는 항상 중요시 되었기에, 이번 Bitnet의 논문 결과는 주목해야 할 듯 싶음.) 싶습니다.
다만 LLaMA로만 테스트를 하고 퍼포먼스를 비교한 점과 모델 성능테스트는 최대 3B모델에서 까지만 해본 등, 실제 서비스를 중인 LLM의 경우 70B가 넘어가는 경우가 허다하기에 그 부분이 이 논문에서 약간 아쉬운 점이 있습니다.(아마 70B와 같이 정말 큰 모델에서는 퍼포먼스가 꽤 떨어지는 것 같다. figure 3, table4를 보면 70B테스트는 진행하였지만, 퍼포먼스 점수를 게시하지 않은 점에서 의구심이 생깁니다.) LLaMA 말고 다른 오픈소스 LLM의 결과도 없는 것 또한 조금 아쉬운 부분입니다.
하지만 앞서 언급했듯, Bitnet1.58 논문의 핵심은 엣지디바이스와 같이 자원의 절약이 필요한 상황에서 인 것 같습니다. 잘 알아두고 한두번 정도의 예시 테스트만 해본다면 기회만 되면 쉽게 적용할 수 있어보이기에 엣지 디바이스에 관심이 있는 분들은 한번씩 읽어보시면 좋을 것 같습니다.
'AI > Paper Review' 카테고리의 다른 글
| Large Language Models for Data Annotation: A Survey 논문 리뷰 (4) | 2024.02.29 |
|---|---|
| Nemotron-4 15B Technical Report 논문 리뷰 (80) | 2024.02.28 |
| Gemma: Open Models Based on GeminiResearch and Technology 논문 리뷰 (13) | 2024.02.27 |
| LoRA+: Efficient Low Rank Adaptationof Large Models 짧은 논문리뷰 (5) | 2024.02.26 |
| SELF-DISCOVER: Large Language Models Self-Compose Reasoning Structures 논문리뷰 (1) | 2024.02.22 |



