
Gemma: Introducing new state-of-the-art open models
Gemma is a family of lightweight, state\u002Dof\u002Dthe art open models built from the same research and technology used to create the Gemini models.
blog.google
안녕하세요 Simon 입니다. 오늘 소개해드릴 논문은 Google 의 새로운 Open Source LLM "Gemma" 입니다. LLaMA 의 영향일까요? 빅테크 기업들도 앞다투어 오픈소스 모델을 공개하고 있는데요. OpenAI 도 조만간 공개할듯합니다. 과연 Gemini 기반의 Gemma 는 어떻게 탄생한것인지 리뷰해보겠습니다.
Abstrack
Google 의 Gemini기반의 오픈소스 모델 Gemma를 소개합니다. 젬마는 언어의 이해, 추론 및 안전성 에 대한 학술적 벤치마크에서 강력한 성능을 보여줍니다. 모델은 두가지 버전인 2B/7B 를 기준으로 출시를하고, 사전 훈련된 Checkpoint 와 미세 조정된 체크포인트를 조정합니다. 또한 젬마는 18개의 텍스트 기반 작업중에 11개에서 유사한 동일한 크기의 오픈 모델을 능가하는 성능을 보여줍니다.
MMLU 성능이 LLaMA-2 7B ,13B 보다 월등히 높은 벤치마크 결과를 보여준다. MMLU 는 언어모델에서 평가되는 지표중 하나로 전반적인 상식과 지식에 대한 평가다. 라마13B 보다 압도적으로 높은 벤치마크 성능을 보면 이례적이라 할 수 있다. Reasoning(추론) 능력또한 엄청나게 차이가 나는 모습을 볼 수 있다. 근데 Gemini 공개 때도 구글이 이런 지표 관련해서 근본없이 다른 설정값을 통해 GPT와 비교를 해서 자기 벤치마크가 GPT를 뛰어넘었다 한 사례가 있기 때문에 이게 과연 정확한가? 에 대한 의문은 들기는 한다.
Introduce
Gemma vs LLM
Gemma는 Gemini를 만든 팀에서 6T 토큰의 텍스트로 학습을 시켰으며, Gemini 와 유사한 아키텍처와, 데이터 및 학습을 진행하였다고 한다. Gemini 와 마찬가지로 이 모델들은 텍스트 영역에서 강력한 범용 능력을 달성하며, 규모에 따른 최첨단 이해력과 추론능력을 가지고 있는데. Google 은 이 Gemma 에 관한 Fine-tunning code, Checkpoin , 추론 및 서비스를 위한 베이스 코드도 제공을 한다.
Gemma 는 2가지의 크기로 제공합니다. Google의 TPU에서 효율적인 배포 및 개발을 위한 70억개의 7B 파라미터 모델과 모델과 CPU 및 Ondevice 응용프로그램을 위한 20억개의 파라미터 2B모델을 공개하였습니다.
Google 은 그동안 Word2vec, T5, Transformers, BERT, T5X를 포함한 개방형 모델 을 통해 오픈소스 생테계에 기여와 함께 발전을 해왔습니다.
Gemma를 공개함으로써 오픈소스 생태계에 기여하겠다는 Google 의 입장이다. 사실 Google deepmind 가 없었다면 AI 가 이정도까지 발전했을까? 라고 생각이 든다.
Model Architecture
Gemma 모델 아키텍처는 트랜스포머 디코더를 기반으로 합니다. 아키텍처의 핵심 파라미터는 표 1에 요약되어 있습니다. 모델은 8192 토큰의 컨텍스트 길이로 훈련됩니다.
2B 모델은 Multi-Query Attention을 사용하였고, 7B 모델 같은 경우는 Multi-head-Attention 을 사용하였습니다.
Transformer의 Multi-Head Attention과 Transformer에서 쓰인 다양한 기법
앞서 우리는 입력으로 주어진 sequence에서 어떠한 부분에 주목할지를 예측에 반영하는 attention 기법을 배웠다. 이러한 Self-Attention에서 좀 더 나아가 head를 여러 개 사용하여 주어진 데이터를 이해
glanceyes.com
효율적인 학습을 위해서 Multi-Head-Attention 을 사용하는 예제나 Fine-tunning 방법들이 있는데요. 위와 같이 Query, Key, Values를 기존의 어텐션 메커니즘처럼 한번에 계산하는 게 아니고 , 분할 한 후에 계산 후 합산하는 방식을 채택하여 사용을 한게 특징입니다.
멀티 헤드 어텐션의 메커니즘에 대해 조금더 궁금하신분들은 위의 블로그를 참고 바랍니다. 잘 설명되어있습니다.
RoPE 임베딩 방식 사용: 절대 위치 임베딩을 사용하는 대신, 각 층에서 회전 위치 임베딩을 사용하며, 입력과 출력에 걸쳐 임베딩을 공유하여 모델 크기를 줄입니다.
GeGLU Activations : 표준 ReLU 비선형성은 GeGLU 활성화 함수로 대체됩니다.

PalM 같은 경우는 Swish 기반의 활성화 함수를 쓴다. 이것 도 조금은 차이점인 듯 하다. 깊게 들어가면 머리가 뜨거우니 skip!!
정규화의 위치 : 트랜스포머 하위 층의 입력과 출력 모두를 정규화하는데, 이는 단지 한 쪽만 정규화하는 표준 관행에서 벗어난 것입니다. 정규화 층으로는 RMSNorm 을 사용합니다
Root Mean Square Layer Normalization
Layer normalization (LayerNorm) has been successfully applied to various deep neural networks to help stabilize training and boost model convergence because of its capability in handling re-centering and re-scaling of both inputs and weight matrix. However
arxiv.org
Layer Norm 보다 효율적이고 대규모 학습에 보통 쓰인다고 합니다. 확실히 Pretrained 영역의 언어모델 학습을 고려할점이 엄청 많구나 매번 생각하게 됩니다. 이걸 해볼수는 있을까?라는 생각과함께.. 빅테크의 전유물 그자체입니다.
Gemma 는 결국 핵심 파라미터에는 모델 차원, 층 수, 피드포워드 숨겨진 차원, 헤드 수 등이 포함됩니다. 또한, 다중 질의 주의, RoPE 임베딩, GeGLU 활성화 함수, 그리고 정규화 위치와 같은 최신 기술들을 통합하여 모델의 효율성과 성능을 향상시키고 있습니다.
Training Infrastructure
Gemma 는 TPUv5e를 사용해서 훈련합니다. 최근에 나온 Groq 를 Google 도 활용할지 궁금하긴한데 확실히 구글의 장점은 TPU를 쓰기 때문에 확실히 강력한점이구나 생각을 하긴 했습니다. Gemini와 마찬가지로 Jax를 활용해서 '단일컨트롤러' 프로그래밍 패러다임을 활용하여 전체 훈련 실행을 조정할 수 있는 단일 파이썬 프로세스를 활성화함으로써 개발 과정을 단순화 합니다. 또 논문에는 탄소 중립에 관련해서 여러가지 실험을 하고 적용했다고 되어있습니다.
Pretraining
Gemma의 훈련데이터는 영어데이터를 기반으로 훈련이 되었으며, Gemmini 와 달리 멀티모달이 아닙니다. SentencePiece 토크나이저의 하위 집합을 호환성을 위해 사용하고, 이는 숫자를 분리하고, 추가 공백을 제거 하지않고, 알려지지 않은 토큰에 대해 바이트 레벨 인코딩으로 의존합니다. 어휘 크기는 256K 입니다.
데이터에서 특정 개인정보 및 기타 민감한 데이터를 제외하고, 또 해로운 저품질 콘텐츠를 제거하기 위해 휴리스틱과 모델 기반 분류기를 모두 사용하였다고 합니다. 사전 혼합데이터에서 모든 평가 세트를 필터링하고, 평가세트 유출에 대해 타켓팅된 오염분석을 실행, 민감 출력의 확산을 최소화 함으로써 암송의 위험을 줄임. 높은 품질의 데이터의 비중을 높이기 위해 코퍼스 혼합을 변경하는 스테이징 훈련을 진행함.
한국어를 따로 Finetunning을 해줘야하기 때문에 Ko-LLM 에서 과연 사용될지 궁금하다
Instruction Tuning
Gemma 2B와 7B를 텍스트만, 영어만을 대상으로 한 합성 및 인간이 생성한 프롬프트-응답 쌍의 혼합에 대한 지도된 미세 조정(SFT)과, 영어만을 대상으로 한 라벨이 붙은 선호도 데이터에 대해 훈련된 보상 모델과 고품질 프롬프트 세트를 기반으로 한 정책을 사용한 인간 피드백으로부터의 강화 학습(RLHF)을 통해 미세 조정합니다. 우리는 이 두 단계가 모두 모델 출력에 대한 하류 자동 평가 및 인간 선호도 평가의 성능 향상에 중요하다는 것을 발견했습니다.
Supervised Fine-Tuning
보류된 프롬프트에 대하여 이를 무작위로 섞고 , 더 크고 능력이 높은 모델에게 두 응답 사이의 선호도를 표현하도록 요청 후 지시사항 따르기, 사실성, 창의성, 안전성과 같은 특정능력을 강조하기 위해 다른 프롬프트 세트가 구성된다. Chain of Thought 프롬프팅을 활용하여 루프릭 및 헌장 사용과 같은 여러기술을 사용해서 인간의 선호도와 일치하도록 합니다.
Filtering
합성 데이터를 사용할 때, 우리는 여러 단계의 필터링을 거쳐 특정 개인 정보, 안전하지 않거나 유독한 모델 출력, 잘못된 자기 식별 데이터, 또는 중복된 예시들을 제거합니다. Gemini를 따라, 문맥 내 속성 부여, 회피, 거절을 장려하는 데이터의 부분 집합을 포함하는 것이 여러 사실성 지표에서 성능을 향상시킬 수 있으며, 다른 지표에서 모델 성능을 저하시키지 않는 것으로 나타났습니다. 최종 데이터 혼합물과 지도 미세 조정 레시피, 조정된 하이퍼파라미터를 포함하는 것은 도움이 되는 것을 향상시키는 동시에 안전성 및 환각과 관련된 모델 피해를 최소화하는 기준에 따라 선택되었습니다.
Pormatting
지시사항 튜닝된 모델은 특정 서식 지정자를 사용하여 훈련되며, 이는 훈련 및 추론 시 모두 추가 정보를 지시사항 튜닝 예제에 주석으로 달기 위한 것입니다. 이는 두 가지 목적을 가집니다: 1) 대화에서의 역할을 나타내는 것, 예를 들어 사용자 역할과 2) 대화에서의 차례를 구분하는 것, 특히 다차례 대화에서 중요합니다. 이 목적을 위해 토크나이저에서 특별 제어 토큰이 예약되어 있습니다. 서식 지정자 없이도 일관된 생성을 얻을 수는 있지만, 모델에 대해 분포 외의 것이 될 것이며, 아마도 더 나쁜 생성물을 생산할 가능성이 매우 높습니다.
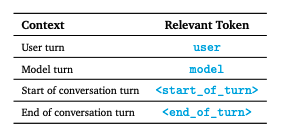
우리가 쓰는 NLP task 에서 시작토큰 <sos> <eos> 라고 생각하면 된다. user, model 대화주체를 구분해줘야하기 때문이다. 패딩토큰을 어떻게 처리하는지는 자세하게 나와있지는 않다.
Reinforcement Learning from Human Feedback(RLHF)
우리는 감독 학습으로 미세 조정된 모델을 RLHF를 사용하여 추가로 미세 조정했습니다 우리는 인간 평가자들로부터 선호도 쌍을 수집하고, Bradley-Terry 모델(N 개의 개체들을 한 쌍 씩 비교하여 평가한 결과들을 사용하여, 전체 개체의 순위를 매기는 방법) 하에서 보상 함수를 훈련시켰습니다. 이는 Gemini와 유사한 방식입니다. 정책은 REINFORCE 변형을 사용하여 이 보상 함수를 최적화하도록 훈련되었으며, 초기에 조정된 모델에 대한 Kullback-Leibler 정규화 항을 포함합니다. SFT 단계와 유사하게, 하이퍼파라미터를 조정하고 보상 해킹 을 추가로 완화하기 위해, 우리는 높은 용량의 모델을 자동 평가자로 사용하고 기준 모델에 대한 단면 비교를 계산했습니다.
Evaluation
자동화된 벤치마크와 사람의 평가를 모두 사용하여 광범위한 영역에서 Gemma를 평가합니다.
Human Preference Evaluations

미세 조정된 모델에 대한 표준 학술 벤치마크를 실행하는 것 외에도, 우리는 최종 출시 후보를 인간 평가 연구에 보내 Mistral v0.2 7B Instruct 모델 과 비교하도록 했습니다. 창의적 글쓰기 작업, 코딩, 그리고 지시 사항을 따르는 것을 요청하는 약 1000개의 보류 중인 프롬프트 컬렉션에서, Gemma 7B IT는 51.7%의 긍정적인 승률을 가지며 Gemma 2B IT는 Mistral v0.2 7B Instruct에 대해 41.6%의 승률을 가집니다.
Automated Benchmarks
Gemma 모델들은 물리적 추론, 사회적 추론, 질문 응답, 코딩, 수학, 상식 추론, 언어 모델링, 독해 등 다양한 도메인에서 성능을 측정합니다. 대부분의 자동 벤치마크에서 Gemini와 동일한 평가 방법론을 사용하며, 특히 Mistral과 비교하여 성능을 보고하는 경우에는 Mistral 기술 보고서의 방법론을 가능한 한 밀접하게 복제합니다. 이러한 구체적인 벤치마크에는 ARC, CommonsenseQA, Big Bench Hard, AGI Eval (영어만) 등이 포함됩니다. LLaMA-2에 대한 평가는 라이선스 제한으로 인해 실행할 수 없었으며, 이전에 보고된 메트릭만 인용합니다.
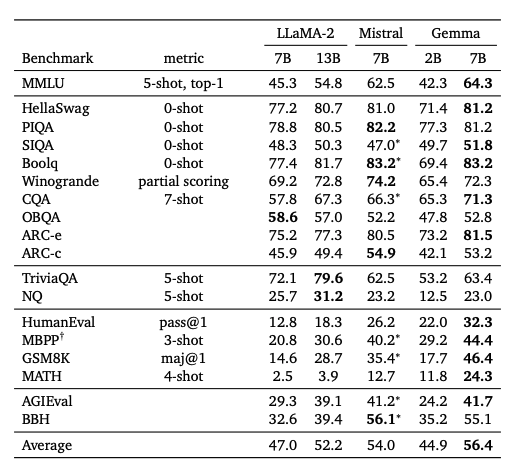
Gemma 모델들은 특히 수학 및 코딩 벤치마크에서 강력한 성능을 보였습니다. 일반적인 분석 능력을 벤치마킹하기 위해 사용되는 수학 작업에서, Gemma 모델들은 GSM8K와 더 어려운 MATH 벤치마크에서 다른 모델들을 최소 10점 이상 앞섭니다. 마찬가지로, HumanEval에서 다른 오픈 모델들보다 최소 6점 이상 높은 성능을 보였습니다. 심지어 코드로 미세 조정된 CodeLLaMA-7B 모델들보다도 MBPP에서 더 높은 성능을 보였습니다(CodeLLaMA는 41.4%의 점수를 달성한 반면 Gemma 7B는 44.4%를 달성했습니다)
Memorization Evaluations
최근의 연구에 따르면, 정렬된 모델들이 새로운 적대적 공격에 취약할 수 있으며, 이러한 공격은 모델들이 분열되게 하고 때때로 훈련 데이터를 그대로 복사하여 내놓게 만들 수 있다고 합니다. 이러한 문제를 조사하기 위해, Gemma 사전 훈련 모델들의 기억화(메모리제이션)를 테스트했으며, 주로 '발견 가능한 기억화'에 초점을 맞추었습니다. 이는 모델의 기억화에 대한 합리적인 상한선으로 여겨지며, 여러 연구에서 사용된 일반적인 정의입니다.
평가를 위해 각 코퍼스에서 10,000개 문서를 샘플링하고, 모델이 텍스트의 정확한 연속을 정확히 일치시키는 경우에만 텍스트를 기억화된 것으로 분류하였습니다. 그러나, 대략적인 기억화도 고려하여, 10% 편집 거리 임계값을 사용하였습니다. Gemma 사전 훈련 모델과 비슷한 크기의 PaLM 및 PaLM 2 모델과 비교했을 때, 비슷하게 낮은 기억화 비율을 발견했습니다.
개인 데이터의 기억화에 대해서는, Gemma 사전 훈련 모델이 안전하고 신뢰할 수 있도록 특정 개인 정보와 기타 민감한 데이터를 훈련 세트에서 자동으로 필터링하는 기술을 사용했습니다. 가능한 개인 데이터 발생을 식별하기 위해 Google Cloud Data Loss Prevention (DLP) 도구를 사용했으며, 이 도구는 개인 데이터의 여러 카테고리(예: 이름, 이메일 등)를 기반으로 세 가지 심각도 수준을 출력합니다. 결과적으로, 민감한 데이터의 기억화 사례는 발견되지 않았으며, '개인'으로 분류된 데이터의 일부가 기억화되는 것을 발견했습니다. 그러나 이 도구는 많은 오진을 내놓을 수 있기 때문에, 식별된 개인 데이터의 양에 대한 우리의 결과는 가능한 과대평가일 수 있습니다.
Responsible Deployment
책임감 있는 배포
Google의 이전 AI 기술 출시와 마찬가지로, 우리는 예상되는 사회적 영향을 식별, 측정 및 관리하기 위해 모델의 책임 있는 개발 및 배포에 대한 구조적 접근 방식을 따릅니다. 이는 최근 Gemini 출시와 같이 이전 학술 문헌(Weidinger et al., 2021), 업계 전반에 걸쳐 수행된 유사한 이전 연구(Anil et al., 2023), 내부 및 외부 전문가와의 지속적인 참여, 그리고 새로운 모델 취약점을 발견하기 위한 비구조적 시도들에 근거합니다.
혜택
AI 과학 및 기술의 개방성은 상당한 혜택을 가져올 수 있다고 믿습니다. 오픈소싱은 과학과 혁신의 주요 동력이며 대부분의 상황에서 책임 있는 관행입니다. 그러나 이는 현재 또는 미래에 해를 끼칠 수 있는 도구를 제공하는 위험과 균형을 맞춰야 합니다. Google은 오랫동안 연구 혁신에 대한 보다 넓은 접근을 제공하는 데 전념해 왔으며, Gemma를 AI 개발 생태계에 출시함으로써 다운스트림 개발자가 과학, 교육, 예술 등의 분야에서 유익한 애플리케이션을 만드는 데 도움이 될 것이라고 믿습니다.
위험
LLM의 악의적 사용, 예를 들어 딥페이크 이미지, AI 생성 가짜 뉴스, 불법 및 불쾌한 자료의 생성은 개인과 기관 수준에서 해를 끼칠 수 있습니다 또한 모델 가중치에 대한 접근을 제공하는 것은 API 뒤에 모델을 출시하는 것과는 다른 책임 있는 배포에 대한 새로운 도전을 제기합니다.
완화 조치
Gemma 모델군에 대한 이러한 방어층이 없어도, 우리는 프리트레이닝 데이터에서 편향을 필터링하고 측정하고, 표준화된 AI 안전 벤치마크를 통해 안전을 평가하며, Gemma의 외부 사용과 관련된 위험을 더 잘 이해하기 위해 내부적으로 레드 팀을 구성하는 등 이러한 위험을 방어하기 위해 노력했습니다.
평가
최종적으로, 기존 생태계 내에서 접근 가능한 더 큰 시스템의 능력을 고려할 때, Gemma의 출시가 전반적인 AI 위험 포트폴리오에 미미한 영향을 미칠 것이라고 믿습니다. 이러한 점을 고려할 때, 그리고 이 모델들이 연구, 감사 및 다운스트림 제품 개발에 대한 유용성을 고려할 때, 우리는 Gemma가 AI 커뮤니티에 제공하는 혜택이 설명된 위험을 상쇄한다고 확신합니다.
결론
Gemma는 텍스트와 코드를 위한 생성 언어 모델의 공개적으로 이용 가능한 가족을 제시합니다. Gemma는 공개적으로 이용 가능한 언어 모델 성능, 안전성, 그리고 책임 있는 개발의 최신 기준을 전진시킵니다. 우리는 Gemma 모델이 광범위한 안전 평가와 완화 조치를 거친 후 커뮤니티에 순수익을 제공할 것이라고 확신합니다; 그러나 이러한 출시는 되돌릴 수 없으며, 공개 모델에서 발생하는 해는 아직 잘 정의되지 않았으므로, 우리는 이러한 모델의 잠재적 위험에 상응하는 평가와 안전 완화 조치를 계속 채택할 것입니다. 추가적으로, 우리의 모델은 6개의 표준 안전 벤치마크와 인간의 직접 비교 평가에서 경쟁 모델을 능가합니다.
결론 아직은 시기상조의 모델인 것 같다.? 후기가 별로 안 좋은 것도 있고, 한국어 잘한다? 이러는 의견도 있고 PPO 가 아닌 강화학습을 통해서(?) 학습을 했나라는 주제도 핫한거 같습니다. 사실 일단 써봐야 알 것 같습니다. 허깅페이스에 Gemma의, 파인튜닝 코드가 같이 배포가 되어있는데 특이하게 Keras 를 통한 파인튜닝 코드여서 환경변수 종속성문제로 Colab 에서 파인튜닝들 많이하는것으로 보였습니다. Kaggle 에도 동시에 이에 관련되어 t4 gpu 를 써서 튜닝하는 코드도 있고 , 점점 리소스가 많아지는 것 같습니다.
Gemma 한국어 SQL챗봇 LoRA 파인튜닝 빠른실행
이번에는 Gemma를 이용해서 한국어를 SQL로 변환하여 DB를 쿼리하는 챗봇을 만들어보겠습니다. 함께보기 Chinook 데이터베이스 Chinook 데이터베이스는 디지털 미디어 스토어를 모델링한 오픈 소스 샘
tykimos.github.io
벌써 AI Factory의 김태영님이 파인튜닝을 해보고, SQL 관련 Task 로 튜닝을 해본 글을 봤는데 잘하는거 같기도 해보였습니다. 근데 아직 Ko-LLM 에는 진입이 안되는거보면 이유가 있겠지 싶기도하고, 일단 한번 파인튜닝을 해봐야 알 것 같습니다.
'AI > Paper Review' 카테고리의 다른 글
| Large Language Models for Data Annotation: A Survey 논문 리뷰 (5) | 2024.02.29 |
|---|---|
| Nemotron-4 15B Technical Report 논문 리뷰 (81) | 2024.02.28 |
| LoRA+: Efficient Low Rank Adaptationof Large Models 짧은 논문리뷰 (6) | 2024.02.26 |
| SELF-DISCOVER: Large Language Models Self-Compose Reasoning Structures 논문리뷰 (1) | 2024.02.22 |
| [논문 리뷰] DoRA: Weight-Decomposed Low-Rank Adaptation (68) | 2024.02.19 |



