안녕하세요 Simon 입니다.
오늘 소개해드릴 논문은 RAG 관련 논문입니다. 아무래도 RAG가 이제 많이 알려지기도 했고 LLM 의 필수요소로 자리잡고 있습니다.
저희도 일단 RAG 자체는 완벽히 이해하고 구현을 하자 느낌이 강해서 새로운 논문을 리딩한번 해보겠습니다.

Abstract
위 논문은 할루시네이션을 줄이기위해 RAG 검색증강 생성을 사용하였지만 여전히 검색내용과 모순되거나 뒷받침 되지 않는 주장을 할 수 있다는 것을 개선하기 위해 RAGTruth라는 코퍼스를 제시합니다. 연구는 다른 LLM들에서 환각 빈도를 비교하고, 기존 환각 탐지 방법의 효과를 평가합니다. 또한, 고품질 데이터셋을 사용하여 작은 LLM을 미세 조정함으로써, 최신 대규모 모델을 사용하는 기존 방법과 경쟁할 수 있는 환각 탐지 성능을 달성할 수 있음을 보여줍니다
introduce
LLM에서 환각 현상을 탐지하고 줄이기 위한 새로운 접근 방법과 데이터셋(RAGTruth)을 제시하며, 이를 통해 LLM의 신뢰성과 정확성을 향상시키는 방법을 탐구합니다.
- 환각 감소를 위한 방법: LLM의 생애주기 동안 다양한 단계에서 적용될 수 있는 여러 방법이 개발되었습니다. 이에는 사전 훈련(pretraining), 감독된 미세 조정(supervised finetuning), 강화 학습을 통한 인간 피드백(RLHF), 추론 단계에서의 방법 등이 포함됩니다
- 환각 탐지 방법: 모델의 내부 상태를 검사하거나, 외부 데이터 및 도구와 비교하거나, LLM의 자체 검사 능력을 활용하는 방법이 개발되었습니다. -> langchain 으로 모델을 구현후 검증단계의 LLM 을 또 Chaining 하는 모델의 아키텍처 설명들이 많았는데 그런게 아닐까 생각한다.
- RAG의 사용: RAG(Retrieval-Augmented Generation)는 LLM에 최신, 관련 지식을 제공하여 환각을 크게 줄이는 데 사용됩니다. 그러나 RAG를 포함한 개선에도 불구하고, LLM은 여전히 근거 없거나 검색된 참조 자료와 모순되는 진술을 생성할 수 있습니다.
- RAGTruth 데이터셋: 이 논문은 RAG 응용 프로그램을 위한 단어 수준 환각 탐지에 특화된 대규모 고품질 데이터셋인 RAGTruth를 소개합니다. 이 데이터셋은 주요 오픈 소스 및 폐쇄 소스 LLM에서 생성된 약 18,000개의 완전히 주석 처리된 자연스러운 응답을 포함합니다.
- 벤치마킹 및 성능 평가: 이 데이터셋을 사용하여 주요 LLM의 환각 생성 경향을 평가하고 현재 환각 탐지 방법을 평가했습니다. 또한, RAGTruth 데이터셋으로 LLM을 미세 조정함으로써 환각을 식별하는 데 뛰어난 성능을 보였습니다.
- 환각 탐지를 위한 미세 조정: Llama-2-13B 모델을 RAGTruth 훈련 데이터로 미세 조정함으로써 GPT-4를 사용하는 기존 프롬프트 기반 접근 방식과 경쟁할 수 있는 결과를 달성했습니다. 이는 RAGTruth를 사용하여 더 나은 환각 탐지 방법을 개발할 수 있는 잠재력을 보여줍니다.
- 환각 감소: 미세 조정된 환각 탐지기를 사용하면 LLM의 응답에서 환각 발생을 크게 줄일 수 있으며, 이는 GPT-4와 같이 본래 환각 비율이 낮은 모델에서도 개선 효과가 있음을 보여줍니다.
Related Work
Hallucination of Large Language Models
환각은 세가지의 범주로 분류를 할 수 있습니다.
- 입력-충돌 환각(Input-Conflicting Hallucination): 사용자의 입력과 충돌하는 정보를 생성하는 경우입니다.
- 문맥-충돌 환각(Context-Conflicting Hallucination): 주어진 문맥과 충돌하는 정보를 생성하는 경우입니다.
- 사실-충돌 환각(Fact-Conflicting Hallucination): 사실과 충돌하는 정보를 생성하는 경우입니다.
Hallucination Detection Methods
신뢰성을 향상시키기 위해 환각을 탐지하는 다양한 방법
- 내재적 모델 불확실성 지표 사용: Azaria와 Mitchell (2023), Xiao와 Wang (2021), Malinin과 Gales (2021)의 연구에서는 토큰 수준 확률과 엔트로피와 같은 내재적 모델 불확실성 지표를 사용하여 환각을 탐지합니다.
- 대체 모델 사용: GPT-4와 같이 제한된 API를 사용할 때 직접적인 출력 불확실성에 접근할 수 없는 경우, 완전히 접근 가능한 다른 LLM을 대리 모델로 사용하는 방법이 있습니다(Manakul et al., 2023).
- 자연어 추론 모듈 적용: Falke et al. (2019)과 Barrantes et al. (2020)의 연구에서는 기사와 그 요약 사이의 정보 일관성을 확인하기 위해 자연어 추론 모듈을 적용합니다. 이 방법은 사실적 환각을 탐지하는 데 외부 지식이 유용하다는 것을 보여줍니다(Guo et al., 2022; Mallen et al., 2022).
- LLM의 내재된 능력 활용: Xiong et al. (2023)과 Manakul et al. (2023)은 내부 상태나 외부 데이터 및 도구에 의존하지 않고 환각을 탐지하는 것을 목표로 하는, 말하기 기반(Verbalize-based) 및 일관성 기반(Consistency-based) 방법과 같은 기술을 제안합니다.
Hallucination Evaluation Datasets
환각 데이터셋은 대규모 언어 모델(Large Language Models, LLMs)의 출력에서 근거 없거나 거짓으로 주장된 진술을 수동으로 식별하는 노동 집약적인 작업이 필요합니다. 이러한 데이터셋은 RAG(Retrieval-Augmented Generation) 시나리오에서 특히 가치가 있습니다. RAG 시나리오에서는 환각의 발생 빈도가 상대적으로 낮기 때문입니다.
합성 데이터셋(Synthetic Dataset): 이러한 데이터셋은 일부러 언어 모델을 환각 반응을 생성하도록 유도하거나 출력에 지식 충돌을 삽입하는 방법을 포함합니다(Li et al., 2023; Longpre et al., 2021). 이 방법들은 환각 반응을 대량으로 생성하는 데 효과적이지만, 이러한 반응들이 자연스럽게 생성된 반응과 같은 분포를 따르지 않을 수 있습니다.
수동으로 제작된 데이터셋(Manually-Crafted Dataset): 이러한 데이터셋은 LLM의 실제 생성 능력을 더 가깝게 나타냅니다(Vu et al., 2023; Lewis et al., 2021). 그러나 주석을 달기 위한 상당한 노동과 비용 때문에 데이터셋의 크기와 길이가 제한되고, 품질이 일관되지 않을 수 있습니다.
RAG 시나리오에서 환각 탐지를 용이하게 할 수 있는 상당한 크기와 품질을 갖춘 수동으로 큐레이트된 데이터셋이 부족합니다. 이러한 문제를 해결하기 위해, 논문의 저자들은 데이터 수집 파이프라인을 소개합니다. 이 파이프라인은 다음 두 단계를 포함합니다: 1) 여러 LLM과 자연스러운 프롬프트를 사용하여 응답을 생성하는 단계, 2) 인간 평가자가 LLM 응답에서 환각된 부분을 주석 처리하는 단계입니다.
데이터 수집 파이프라인. 데이터-텍스트 변환 작업을 예로 들면, 데이터 수집 파이프라인은 다음과 같습니다.
-> 아무래도 Dataset 자체를 만드는 것은 매우 노동집약적인 일이기 때문이다.
Construction Process of RAGTruth
Response Generation
작업 및 데이터 소스
응답 생성을 위해 세 가지 널리 인정받는 RAG 작업을 선택했습니다: 요약(Summarization), 질문 응답(Question Answering), 데이터-텍스트 생성(Data-to-Text generation).
- 요약 작업: CNN/Daily Mail 데이터셋(See et al., 2017)의 훈련 세트에서 무작위로 문서를 선택하고, 유명 뉴스 플랫폼의 최근 뉴스 기사도 사용했습니다. LLM에 각 소스 문서에 대한 요약을 생성하도록 요청했습니다.
- 질문 응답 작업: MS MACRO 데이터셋(Nguyen et al., 2016)의 훈련 세트에서 무작위로 샘플링했습니다. 주석 비용을 줄이기 위해 각 질문에 대해 검색된 3개의 문단만 유지했습니다. 그런 다음 LLM에게 검색된 문단만을 기반으로 각 질문에 대한 답변을 생성하도록 요청했습니다.
- 데이터-텍스트 생성 작업: Yelp Open Dataset(Yelp, 2021)에서 레스토랑과 나이트라이프 카테고리의 비즈니스를 무작위로 샘플링했습니다. 이 데이터셋은 구조화된 데이터 소스로 사용되었습니다. 주석 과정을 간소화하기 위해 다음과 같은 비즈니스 정보 필드에만 초점을 맞췄습니다: BusinessParking, RestaurantsReservations, OutdoorSeating, WiFi, RestaurantsTakeOut, RestaurantsGoodForGroups, Music, Ambience. 그런 다음 LLM에게 각 비즈니스에 대한 객관적인 텍스트 소개를 생성하도록 요청했습니다.
모델
응답 생성을 위해 다음과 같은 여섯 가지 강력한 지시 사항을 따르는 모델을 사용했습니다: OpenAI의 GPT-3.5-turbo-0613과 GPT-4-0613(OpenAI, 2023); Mistral AI의 Mistral-7b-Instruct(Jiang et al., 2023); Meta의 Llama-2-7B-chat, Llama-2-13B-chat, Llama-2-70B-chat(4bit quantized)(Touvron et al., 2023).
Human Annotation
인공지능(AI)이 생성한 환각을 식별하는 과정에 대해 설명합니다. 이 작업은 논리적 흐름을 이해하고, 미묘한 부정확성과 일관성 없는 부분을 발견하는 데 주의를 기울여야 하므로, 비판적 사고 능력과 세심한 주의가 필요합니다. 또한, 뉴스 관련 샘플 데이터에서 논의되는 주제를 이해하기 위해 미디어 리터러시와 현재 사건에 대한 지식이 중요합니다. 따라서, 영어에 능통하고 관련 분야의 학사 학위를 가진 주석자를 선택했습니다.
주석자들은 Label Studio(Tkachenko et al., 2020-2022)를 사용하여 주석 작업을 수행했습니다. 각 라벨링 작업은 다음 구성 요소를 포함하는 한 페이지 내에서 제시됩니다: 1) AI 모델에 제공된 원래 입력 텍스트, 2) 다른 AI 모델이 생성한 6개의 응답 세트.
참조: 구절 1:1 성별 확인에만 관심이 있는 경우 17주부터 가능합니다. 2 그보다 빠르면 결과가 정확하지 않을 수 있으므로 침실에 페인트를 추가로 칠해야 할 수도 있습니다. 3 좋은 사진을 얻으려면 3D 초음파는 20주에서 32주 사이에 가장 잘 수행되며, 24주에서 30주 사이에 가장 좋은 사진을 얻을 수 있습니다.
패시지 2:...
패시지 3:...
질문: 초음파를 받기 위해 어떻게 준비해야 하나요?
답변: 주어진 구절에 따라 초음파 검사를 준비하는 방법은 다음과 같습니다, 정확한 결과를 얻으려면 최소 임신 17주까지 기다리세요. 3D 초음파의 경우, 다음과 같이 예약하세요. 최상의 사진을 위해 임신 20주에서 32주 사이에 예약하세요...
환각 여부: 예
촬영 기간: 최상의 사진을 위해 임신 20주에서 32주 사이에 예약하세요.
유형: 명백한 충돌
- 명백한 충돌(Evident Conflict): 생성된 내용이 원래 입력과 직접적인 모순이나 반대를 나타낼 때입니다. 이러한 충돌은 명확한 사실적 오류, 잘못된 이름, 잘못된 숫자 등 광범위한 맥락 없이 쉽게 검증할 수 있습니다.
- 미묘한 충돌(Subtle Conflict): 생성된 내용이 원래 입력에서 벗어나거나 다르게 해석되어 의도된 문맥적 의미를 변경할 때입니다. 이러한 충돌은 종종 다른 함의나 심각성을 가진 용어로 대체되며, 그 문맥적 적용에 대한 더 깊은 이해가 필요합니다.
- 명백한 근거 없는 정보 도입(Evident Introduction of Baseless Information): 생성된 내용이 원래 입력에서 뒷받침되지 않는 정보를 포함할 때입니다. 이는 증거나 지지가 없는 가상, 허구, 환각적인 세부 사항의 생성을 포함합니다.
- 미묘한 근거 없는 정보 도입(Subtle Introduction of Baseless Information): 생성된 내용이 추론된 세부 사항, 통찰력 또는 감정을 포함하여 원래 입력을 넘어서 확장될 때입니다. 이 추가 정보는 검증 가능성이 없으며, 명시적인 사실보다는 주관적인 가정이나 일반적으로 관찰되는 규범을 포함할 수 있습니다.
Annotations for Adaptive Evaluation
잘못된 거부 응답
질문-응답 작업에서는 모델이 관련 정보가 부족한 맥락에서 답변을 거부하도록 요구됩니다. 그러나 관련 맥락이 존재함에도 불구하고 모델이 잘못 거부하는 경우가 있습니다. 이러한 거부 응답은 환각으로 표시되지 않고 대신 'incorrect_refusal'로 표시됩니다.
Null 값 처리의 차이
데이터-텍스트 작업에서는 특정 필드가 때때로 null 값으로 되어 있습니다. 생성된 결과에서 일부 모델들이 종종 null을 false로 해석하는 것을 관찰했습니다. 데이터셋에서 부정을 나타내는 더 일반적인 표현이 불리언 값 False 또는 텍스트 No인 경우, 이러한 인스턴스를 환각(명백한 근거 없는 정보 도입)으로 표시하고, 'due_to_null'이라는 특별한 범위 수준 주석을 제공했습니다.
RAGTruth의 기본 통계
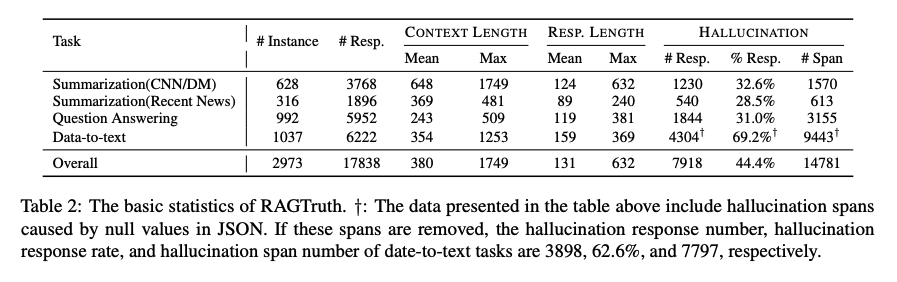
이 표에는 JSON에서 null 값으로 인해 발생한 환각 범위가 포함되어 있습니다. 이러한 범위를 제거하면 데이터-텍스트 작업의 환각 응답 수, 환각 응답 비율, 환각 범위 수는 각각 3898, 62.6%, 7797이 됩니다
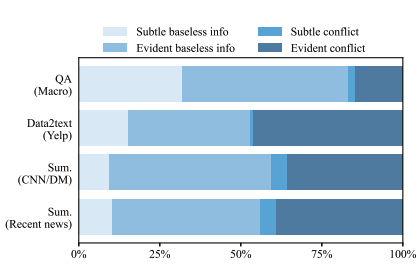
사용자는 이러한 범위를 환각으로 간주할지 여부를 독립적으로 선택할 수 있습니다. 또한 평가 스크립트에 사용자가 이러한 범위를 평가에 포함할지 여부를 결정할 수 있는 옵션이 포함되어 있습니다.
Hallucination Benchmark Analysis
기본 통계
RAGTruth 데이터셋은 총 2,973개의 데이터 인스턴스를 포함하며, 이 중 요약 작업에 944개, 질문 응답 작업에 992개, 데이터-텍스트 생성 작업에 1,037개가 할당됩니다.
각 인스턴스는 6개의 다른 모델로부터 생성된 응답을 포함합니다.
RAGTruth 데이터셋은 기존의 환각 탐지 데이터셋보다 긴 프롬프트와 응답 길이를 특징으로 합니다.
환각 통계
환각 유형: 맥락과 충돌하는 정보보다 맥락에서 근거 없는 정보를 생성하는 것이 더 흔한 것으로 나타났습니다. 두 주요 범주인 근거 없는 정보와 충돌 중에서도, 명백한 근거 없는 정보와 명백한 충돌이 상당한 비율을 차지합니다.
작업별 환각: 데이터-텍스트 작업에서 환각 빈도가 가장 높았습니다. 요약 작업의 환각 비율은 상대적으로 낮았으며, 최신 뉴스와 오래된 뉴스 간에 환각 비율의 큰 차이는 나타나지 않았습니다.
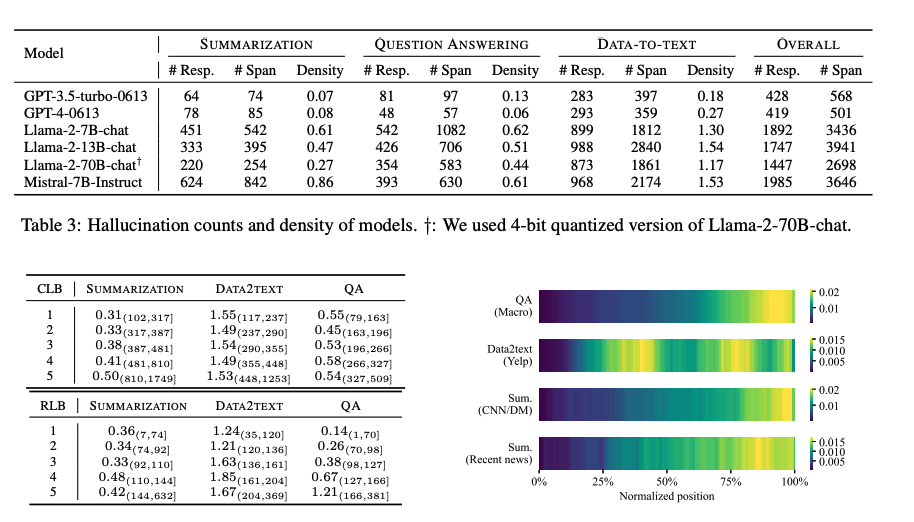
모델별 환각: OpenAI의 두 모델이 다른 모델들에 비해 상대적으로 낮은 환각 비율을 보였으며, 특히 GPT-4-0613이 가장 낮은 환각 빈도를 보였습니다. Llama2 시리즈에서는 모델 규모와 환각 밀도 간에 명확한 부정적 상관관계가 관찰되었습니다.
환각 vs 길이
데이터를 각 작업 유형별로 다섯 개의 동일한 버킷으로 나누고, 각 버킷 내에서 응답당 평균 환각 범위 수를 계산했습니다. 일반적으로 맥락 길이나 응답 길이가 증가함에 따라 평균 환각 수가 증가하는 경향이 있습니다.
환각의 위치
환각은 일반적으로 응답의 끝 부분에서 발생할 가능성이 더 높으며, 이 패턴은 특히 질문 응답 및 요약 작업에서 두드러집니다. 데이터-텍스트 작업에서는 응답의 첫 번째 절반에서 환각이 상대적으로 더 자주 발생합니다.
Experimental Setup
Hallucination Detection Algorithms
- 환각 탐지 프롬프트: GPT-4-turbo 및 GPT-3.5-turbo를 사용하여 주어진 참조-응답 쌍에 환각된 내용이 포함되어 있는지 평가하고, 응답에서 해당 환각된 범위를 식별하도록 수동으로 제작된 프롬프트입니다.
- SelfCheckGPT (Manakul et al., 2023): SelfCheckGPT는 샘플링 기반의 제로-리소스 방법을 사용하여 블랙박스 모델의 응답을 팩트 체크합니다. RAGTruth의 각 응답을 처리할 때 다른 모델의 5개 응답이 참조로 사용되며, GPT-4-turbo/GPT-3.5-turbo가 일관성을 검증하는 데 사용됩니다.
- LMvLM (Cohen et al., 2023): LMvLM은 두 언어 모델 간의 멀티턴 상호작용을 사용하여 교차 검증을 통해 일관성 없는 부분을 발견하는 접근 방식입니다.
- LLM 미세 조정: Llama-2-13B는 RAGTruth의 훈련 세트를 사용하여 미세 조정되었습니다. 이 모델은 적절한 지시사항이 포함된 맥락-응답 쌍을 입력으로 받아 환각 범위를 목표 생성 출력으로 취급합니다. LoRA (Hu et al., 2021) 미세 조정을 사용하여 초기 학습률 3e-4로 3 에포크 동안 4개의 A100 GPU에서 훈련을 진행했습니다.

Data Split
모든 탐지 알고리즘은 동일한 RAGTruth 테스트 세트에서 테스트되며, 이는 각 작업 유형에서 무작위로 선택된 150개 인스턴스로 구성된 총 450개 인스턴스로 구성됩니다. 나머지 데이터는 앞서 언급한 대로 Llama-2-13B 모델을 미세 조정하는 데 사용됩니다.
Evaluation Metrics
응답 수준 탐지: 각 탐지 알고리즘과 그 변형에 대해 정밀도(precision), 재현율(recall), F1 점수를 다양한 작업에 걸쳐 보고합니다.
범위 수준 탐지: 생성된 범위와 인간이 라벨링한 범위 사이의 겹침을 계산하고, 문자 수준에서 정밀도, 재현율, F1 점수를 보고합니다.
Experimental Results
Response-level Detection
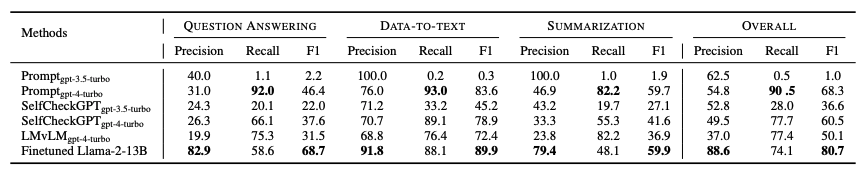
RAG 컨텍스트에서 환각 탐지는 모든 기존 탐지 방법에 대해 여전히 상당한 도전 과제입니다. 참조 정보가 제공되더라도 생성된 응답에는 여전히 환각이 포함될 수 있으며, 현재 LLM은 이를 신뢰할 수 있게 식별하지 못합니다. 가장 진보된 LLM인 GPT-4-turbo는 평균 F1 점수가 68.3%에 불과합니다. 이는 환각된 응답을 식별하는 데 어려움. 널리 사용되는 GPT-3.5-turbo는 대부분의 예시를 비환각으로 잘못 식별하는 경우가 많아, 자연스럽게 발생하는 환각을 탐지하는 데 어려움. SelfCheckGPT는 GPT-4-turbo를 사용할 때 평균 F1 점수가 60.5%, GPT-3.5-turbo를 사용할 때 36.6%로 만족스럽지 못한 성능을 보입니다. 인간이 라벨링한 고품질 훈련 세트를 사용하여 미세 조정된 Llama-2-13B는 평균 80.7%의 F1 점수로 가장 좋은 성능을 달성합니다. 이는 RAGTruth 데이터가 모델의 환각 탐지 능력을 향상시키는 데 효과적임을 보여줍니다.
Span-level Detection

현재의 탐지 방법은 범위 수준에서 최적이 아닌 성능을 보여줍니다. GPT-4-turbo는 많은 비환각 내용을 잘못 분류하여 낮은 정밀도를 보입니다. 미세 조정된 모델은 평균 F1 점수가 48.4%로 환각된 범위를 식별하는 능력이 향상되었지만, 여전히 완벽한 탐지에는 미치지 못합니다. 명백한 환각의 탐지는 미묘한 환각의 탐지보다 더 효과적입니다.
Hallucination Suppression
- 실험 설정: 테스트 세트의 450개 인스턴스에 대해, 유사한 환각 밀도를 가진 두 다른 모델에서 생성된 두 응답 중 최종 출력을 선택하기 위한 두 가지 전략을 사용했습니다. 첫 번째 전략은 예측된 환각 범위가 적은 응답을 선택하는 것이고, 두 번째 전략은 감지된 환각 범위가 없는 응답을 선택하는 것입니다. 두 후보 응답에서 감지된 환각 범위 수가 동일한 경우, 하나를 무작위로 선택합니다.
- 결과: 환각 탐지기의 도움으로, 두 전략 모두 환각 비율을 크게 줄일 수 있습니다. 상대적으로 작은 Llama-2-7B-chat 및 Mistral-7B-Instruct 모델의 경우, 무작위 선택에 비해 첫 번째 전략은 환각 비율을 21.8% 줄였고, 두 번째 전략은 56.6%를 줄였습니다. GPT-3.5-Turbo 및 GPT-4와 같이 환각 비율이 낮은 모델에서도, 미세 조정된 환각 탐지기를 사용하여 샘플링하면 환각 비율을 더욱 줄일 수 있습니다. 두 전략은 각각 환각 비율을 41% 및 52.9% 줄였습니다.
Conclusion
- RAGTruth 소개: RAGTruth는 자연스럽게 생성된 환각을 포함하는 대규모 코퍼스로, 검색-증강 생성(Retrieval-Augmented Generation, RAG) 시나리오에 맞춰 세부적인 단어 수준 주석이 특징입니다.
- 환각과 다양한 요인 간 상호작용 분석: 작업 유형, 사용된 모델, 맥락 설정과 같은 다양한 요인과 환각 간의 상호작용에 대한 심층적인 분석을 포함합니다.
- 환각 탐지 접근법에 대한 실증적 벤치마크: RAGTruth를 사용하여 여러 환각 탐지 접근법에 대한 실증적 벤치마크를 수행했습니다. Llama 모델을 RAGTruth로 미세 조정하면 환각 탐지에서 경쟁력 있는 성능을 달성할 수 있음을 보여줍니다.
- 고품질 데이터셋의 중요성: RAGTruth와 같은 고품질 데이터셋을 사용하면 GPT-4와 같은 일반 모델을 사용하는 프롬프트 기반 방법과 비교하여 효과적인 전문화된 환각 탐지 모델을 개발할 수 있음을 시사합니다.
- 환각 탐지의 도전: RAG 컨텍스트에서, 특히 범위 수준에서 환각을 식별하는 것은 여전히 큰 도전으로 남아 있으며, 현재 방법들은 신뢰할 수 있는 탐지에는 여전히 미치지 못합니다.



