안녕하세요 Simon 입니다
오늘은 Honeybee 라고 KAKAO Brain 에서 개발한 멀티모달 모델에 관련된 논문을 리뷰하려고 합니다.
LLM -> MLLM 에 대한 연구가 확실히 활발하게 이루어지고 있는 듯 합니다.

HoneyBEE
- 카카오브레인이 새로운 인공지능 모델 '허니비(Honeybee)'를 발표, 이미지와 텍스트 입력이 가능한 기능을 갖춤.
- '허니비'는 이미지와 텍스트를 이해하고 답변하는 능력이 있으며, MME 벤치마크에서 높은 점수를 획득.
- 카카오브레인은 허니비를 교육 및 학습 보조 도구로 활용할 계획이며, 지속적인 연구와 개발을 진행할 예정임.
Honeybee: Locality-enhanced Projector for Multimodal LLM
In Multimodal Large Language Models (MLLMs), a visual projector plays a crucial role in bridging pre-trained vision encoders with LLMs, enabling profound visual understanding while harnessing the LLMs' robust capabilities. Despite the importance of the vis
arxiv.org
GitHub - kakaobrain/honeybee: Official implementation of Honeybee
Official implementation of Honeybee. Contribute to kakaobrain/honeybee development by creating an account on GitHub.
github.com
Abstract
사전 훈련된 시각 인코더와 LLM을 연결하는데, 이를 통해 깊은 시각적 이해와 LLM의 강력한 능력을 활용할 수 있습니다. 연구팀은 두 가지 중요한 프로젝터 속성을 확인했다고 합니다. (i) MLLM의 전반적인 효율성에 필수적인 시각 토큰 수를 관리하는 유연성, (ii) 공간적 이해에 필수적인 시각적 특징에서 지역적 맥락을 보존하는 것. 이러한 발견을 바탕으로, 연구팀은 유연성과 지역성이 강화된 새로운 프로젝터 설계를 제안했으며, 이는 두 가지 바람직한 속성을 효과적으로 만족시킨다고 합니다. 또한, 다양하고 다면적인 지시 데이터셋을 효과적으로 활용하기 위한 포괄적인 전략들을 제시합니다. 광범위한 실험을 통해 개별 디자인 선택의 영향을 검토하였습니다.
마지막으로, 제안된 MLLM인 'Honeybee'는 MME, MMBench, SEED-Bench, LLaVA-Bench 등 다양한 벤치마크에서 이전의 최고 수준 방법들을 뛰어넘어 현저히 높은 효율성을 달성했다고 합니다.
1. Introduction
대규모 언어 모델(LLM)이 최근 몇 년 동안 큰 진전을 이루었으며, 이는 주로 지시 튜닝(instruction tuning) 덕분이라고 언급합니다. 시각적 지시 튜닝을 통해 LLM을 다중모드 LLM(MLLM)으로 확장시키는 것이 제안되었으며, 이는 이미지와 같은 시각적 신호를 인지하고 이해하는 데 중요합니다. MLLM의 주요 아이디어는 시각 인코더와 LLM을 연결하는 프로젝터를 도입하고, 시각적 지시 데이터를 사용하여 프로젝터를 학습하는 것입니다. 이러한 간단한 기술은 시각 인코더와 LLM의 사전 훈련된 지식과 능력을 보존하고 활용하게 하며, 결과적으로 MLLM은 이미지로부터 이야기, 시, 광고, 코드 등을 생성하는 등 새로운 능력을 발휘하게 합니다. 이러한 성공은 텍스트를 넘어서는 다양한 모달 입력(예: 비디오, 오디오, 3D 세계, 포인트 클라우드)을 처리하는 MLLM에 대한 연구에 대한 관심을 증가시켰습니다.
MLLM에서 프로젝터는 성능과 효율성 측면에서 중요한 역할을 합니다. 프로젝터는 시각적 특징을 시각적 토큰으로 변환하여 LLM이 이해할 수 있도록 하며, 이는 MLLM의 전반적인 성능에 직접적인 영향을 미칩니다. 그러나 프로젝터는 상대적으로 연구가 덜 되었으며, 대부분의 MLLM은 선형 프로젝터나 추상화기를 단순히 채택합니다. 최근 MLLM은 추상화기를 선형 프로젝터보다 선호하는데, 이는 결과적인 시각적 토큰의 수를 유연하게 처리할 수 있는 다양한 디자인 옵션을 제공하기 때문입니다. 그러나 추상화기는 공간적 이해를 위한 학습 과제에 어려움을 겪고 있습니다. 이는 추상화 과정 중 지역성 인식 설계의 부재로 인해 발생합니다. 이에 비해, 선형 프로젝터는 시각적 특징의 지역적 맥락을 효과적으로 보존합니다.

구체적으로는 지역성 모델링에서 강력한 두 가지 연산인 합성곱과 변형 가능한 주의를 사용하여 C-Abstractor와 D-Abstractor를 도입합니다. 이러한 지역성 인식 디자인의 도입은 MLLM의 전체 성능 향상을 촉진할 뿐만 아니라 LLM의 응답 생성 단계에서의 계산 효율성도 증가시킵니다. 지역성 강화 프로젝터를 갖춘 MLLM, 'Honeybee'와 함께, 저자들은 최첨단 MLLM을 위한 숨겨진 레시피를 제공합니다. 주목할 만한 점은, 최근 MLLM 훈련 전략에는 다양한 지시 데이터를 사용하는 것이 포함됩니다: 1) GPT를 사용한 지시 따르기 데이터셋과 2) 지시화 과정을 거친 시각-언어 작업 데이터셋입니다. 저자들은 이러한 데이터셋을 최대한 활용하기 위한 중요하면서도 덜 탐구된 디자인 선택을 제시하고, 다양한 벤치마크에서 개별 디자인 선택의 영향을 검증합니다.
- 시각적 특징의 지역성 보존과 시각적 토큰 수를 관리하는 유연성이라는 두 가지 중요한 프로젝터 속성을 식별하고, 두 세계의 장점을 모두 달성하는 지역성 강화 추상화기를 제안합니다.
- 다면적 데이터셋 및 지시화 과정을 효과적으로 처리하는 방법을 제안하고, 지시 데이터에서 최대의 이익을 얻습니다.
- 지역성 강화 프로젝터와 탐구된 숨겨진 레시피를 통해, Honeybee는 MME, MMBench, SEED-Bench, LLaVA-Bench 등 다양한 MLLM 벤치마크에서 최고의 성능을 달성합니다.
2. Related Work
2.1. Multimodal Large Language Models
최근 LLM의 지시 따르기 및 일반화 능력의 발전으로 MLLM으로의 확장이 이루어졌습니다. 초기 연구들인 Flamingo와 BLIP-2는 LLM을 시각적 작업에 적용하여 주목할 만한 제로샷 일반화 및 상황 내 학습 능력을 보여주었습니다. 최근 MLLM은 주로 시각적 지시 튜닝을 통해 발전하였는데, 이는 비전-언어 데이터셋을 사용하고 시각적 지시 데이터를 강화하는 것을 포함합니다. 또한, MLLM의 구체화 능력에 중점을 둔 추가 데이터셋을 사용하는 연구도 있습니다. 그러나 최근 MLLM은 프로젝터의 디자인을 깊이 탐구하지 않았으며, 이는 MLLM의 효과성과 효율성에 중요합니다.
2.2. Multimodal Instuction-following Data
GPT-3에서 ChatGPT로의 발전은 지시 따르기 데이터의 중요성을 강조합니다. 마찬가지로, 다양한 지시를 처리하기 위해 MLLM을 훈련시키는 데 시각적 지시 데이터를 통합하는 것이 필수적입니다. 몇몇 연구들은 복잡한 VL 작업을 위한 시각적 지시 데이터를 생성하기 위해 GPT-4와 같은 강력한 LLM을 사용합니다. 또 다른 연구들은 기존 VL 작업 데이터셋을 지시 따르기 형식으로 변환하는 것, 즉 지시화를 탐구합니다. 지시 따르기 데이터셋의 활발한 개발 및 확장에도 불구하고, 이러한 데이터셋을 결합하고 활용하는 방법에 대한 연구는 여전히 미흡합니다.
-> GPT로 Re-Write ? 를 적용해서 Instrucition 을 만들어서 통합 한다(?)
2.3. Benchmarks for MLLM
MME, MMBench, SEED-Bench는 MLLM의 객관적 평가를 위한 종합적인 벤치마크로 소개되었습니다. 이러한 벤치마크는 총체적 및 미세한 지각 분석부터 시각적 추론 작업에 이르기까지 평가 과제의 광범위한 스펙트럼을 포함합니다. 한편, MLLM의 능력이 시각적 스토리텔링 및 자유 형식 텍스트로 지시 따르기와 같은 더 복잡한 VL 작업을 처리할 수 있게 됨에 따라, 다른 유형의 벤치마크가 제안되었습니다. 이는 주관적 평가를 목표로 하며, GPT-4와 같은 강력한 LLM을 사용하여 MLLM의 응답 품질을 평가하는 데 중점을 둡니다.
평가지표에 관련한 설명에 대해 GPT에게 물어봤습니다.
- MME (Multimodal Evaluation):
- 목적: MME는 다양한 시각적과 언어적 정보를 결합해야 하는 작업들을 포함하여 MLLM의 성능을 평가합니다.
- 평가 방식: 이 벤치마크는 주로 이미지와 관련된 질문에 대한 모델의 대답을 평가합니다. 질문은 이미지의 내용을 이해하고 추론하는 능력을 시험합니다.
- 특징: MME는 모델이 시각적 데이터와 언어 데이터를 통합하여 이해하고 처리할 수 있는 능력을 측정합니다. 이는 비주얼 추론, 객체 인식, 상황 이해 등의 능력을 포함합니다.
- MMBench (Multimodal Benchmark):
- 목적: MMBench는 다양한 시각-언어 작업을 포함하여 MLLM의 다양한 능력을 평가하는 데 초점을 맞춥니다.
- 평가 방식: 이 벤치마크는 시각적 내용과 관련된 다양한 작업들을 포함하며, 예를 들어 이미지 캡셔닝, 시각적 질문 응답(VQA), 시각적 추론 등이 있습니다.
- 특징: MMBench는 모델이 시각적 정보와 언어 정보를 어떻게 통합하고, 다양한 시각-언어 작업에 어떻게 적용할 수 있는지를 평가합니다. 이는 MLLM의 다목적성을 평가하는 데 중요합니다.
- SEED-Bench (Scene Understanding Evaluation for Diagnostics Bench):
- 목적: SEED-Bench는 특히 장면 이해 및 시각적 추론 능력에 중점을 두어 MLLM의 성능을 평가합니다.
- 평가 방식: 이 벤치마크는 이미지 내의 복잡한 장면을 해석하고 이를 바탕으로 질문에 답하는 모델의 능력을 평가합니다.
- 특징: SEED-Bench는 모델이 복잡한 시각적 정보를 어떻게 처리하고, 이를 통해 언어적으로 표현하는 능력을 측정합니다. 이는 복잡한 시각적 장면에서의 세부적인 정보 추출 및 추론 능력을 평가하는 데 유용합니다.
세개의 평가지표를 통해서 모델이 시각적인 정보와, 언어 정보를 어떻게 효과적으로 결합하고 처리하는지에 대한 이해를 평가할 수 있어보입니다.
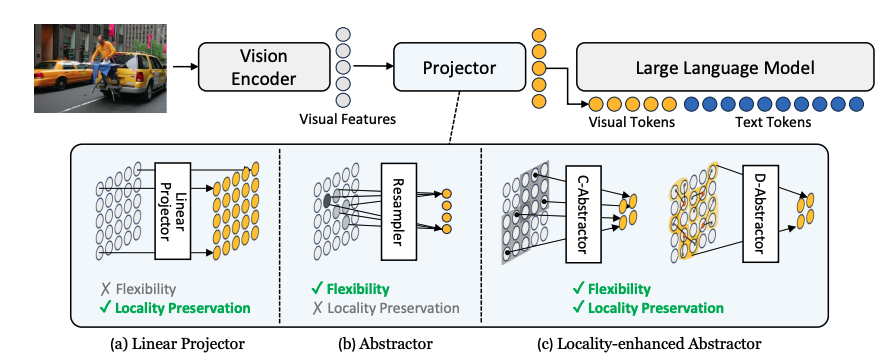
- 선형 프로젝터 (Linear Projector):
- 개념: 이미지가 시각 인코더를 통해 시각적 특징으로 변환된 후, 선형 프로젝터를 사용하여 각 특징을 개별적인 시각적 토큰으로 변환합니다.
- 장점: 이 방법은 이미지의 지역적 맥락을 잘 보존합니다. 즉, 이미지 각 부분의 세부적인 정보를 잘 유지합니다.
- 단점: 유연성이 부족하다는 표시가 있어, 프로젝터가 생성하는 시각적 토큰의 수를 조절하는 데 한계가 있음을 나타냅니다.
- 추상화기 (Abstractor):
- 개념: 추상화기는 시각적 특징을 요약하여 적은 수의 시각적 토큰으로 변환합니다. 여기에는 "Resampler"라는 구체적인 유형의 추상화기가 나타나 있습니다.
- 장점: 유연성이 있다는 표시가 있어, 필요에 따라 생성하는 시각적 토큰의 수를 조절할 수 있음을 나타냅니다.
- 단점: 지역적 맥락 보존이 부족하다는 표시가 있어, 이미지의 모든 부분보다는 중요한 영역에만 집중하여 일부 세부 정보를 소실할 수 있음을 나타냅니다.
- 지역성 강화 추상화기 (Locality-enhanced Abstractor):
- 개념: 이 추상화기는 유연성과 지역적 맥락 보존을 모두 달성합니다. "C-Abstractor"와 "D-Abstractor"라는 두 가지 구체적인 유형이 나타나 있습니다.
- 장점: 유연성과 지역적 맥락 보존 모두 가능하다는 표시가 있어, 이미지의 세부 정보를 잘 유지하면서도 변환 과정에서 효율적으로 시각적 토큰의 수를 조절할 수 있음을 나타냅니다
"C-Abstractor"와 "D-Abstractor"를 포함하여, 시각적 특징을 시각적 토큰으로 변환하는 과정에서 유연성과 지역적 맥락 보존 능력을 모두 달성하도록 설계되었습니다. 이러한 프로젝터는 시각적 특징을 효율적으로 추상화하면서도, 이미지의 중요한 지역적 정보를 손실하지 않게끔 합니다. 따라서 Honeybee 모델은 선형 프로젝터의 지역성 보존 장점과 추상화기의 유연성 장점을 모두 갖춘 프로젝터를 사용하고 있다고 할 수 있습니다.
3. Honeybee: Locality-enhanced MLLM
3.1. Overview
자동회귀적 방식으로 이루어지며, 언어 모델은 이전에 생성된 토큰들과 현재의 다중모드 입력에 기반하여 다음 토큰을 차례로 생성합니다.
멀티모달 입력은 이미지 토큰 Ximg와 텍스트 토큰 Xtext 두 가지 유형으로 구성됩니다. 그 후, 언어 모델은 다중 모달 입력에 기반하여 응답 Y = {wi}L i=1을 예측합니다. 여기서 L은 응답 내 토큰 수를 의미합니다. 따라서 응답은 p(Y|Ximg, Xtext) = ∑Li=1 p(wi |Ximg, Xtext, w<i) 식에 따라 예측됩니다.
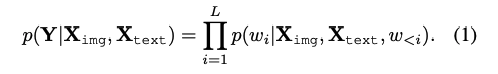
그 후, 언어 모델은 다중 모달 입력에 기반하여 응답 Y = {wi}L i=1을 예측합니다. 여기서 L은 응답 내 토큰 수를 의미합니다. 따라서 응답은 p(Y|Ximg, Xtext) = ∑Li=1 p(wi |Ximg, Xtext, w<i) 식에 따라 예측됩니다. 구조적으로, MLLMs는 1) 비전 인코더, 2) 프로젝터, 3) 대규모 언어 모델(LLM) 세 가지 네트워크로 구성됩니다. 비전 인코더는 상세한 이미지 이해를 위해 영역 수준의 시각적 특징을 제공합니다. 프로젝터는 시각적 특징을 이후의 언어 모델에서 사용할 시각적 토큰으로 변환하는 역할을 합니다. 그 다음, LLM은 융합된 시각적 및 지시 토큰을 처리하고 자동회귀 방식으로 응답을 생성합니다
Efficiency of MLLMs.
MLLM 구조에서, 대규모 언어 모델(LLM)이 전체 계산 및 메모리 소비의 대부분을 차지합니다. 따라서 동일한 LLM을 사용하는 경우, MLLM의 효율성(계산, 메모리 소비, 처리량 측면에서)은 비전 인코더와 프로젝터의 효율성이 아니라, LLM에 공급되는 시각적 토큰의 수에 주로 영향을 받습니다.
Revisiting existing projectors. T
프로젝터는 N개의 시각적 특징을 M개의 시각적 토큰으로 변환합니다. MLLMs의 프로젝터는 선형 투영과 시각적 특징의 추상화 사이의 연산을 채택합니다.
선형 투영은 간단하면서도 효과적이며, 비전 인코더의 지식과 이해력(예: 시각적 특징의 지역성)을 유지하는 데 특히 유용하지만, 시각적 특징과 토큰 간의 일대일 변환(즉, M = N)이라는 본질적인 제약으로 인해 확장성과 효율성 측면에서 도전을 겪습니다.
-> 간단하고 효과적이나 확장성 효율성이 1대1변환에서 좋지 않아 문제 발생
추상화는 시각적 토큰(M)의 수를 결정하는 데 더 적응 가능한 접근 방식을 제공합니다. 예를 들어, ReSampler 와 Q-former 효율성을 위해 일반적으로 N보다 작은 M개의 학습 가능한 쿼리와 크로스 어텐션을 사용하여 시각적 특징에서 시각적 단서를 추출합니다
-> 비전 인코더로부터 얻은 정보가 일부 손실 위험이 존재한다
3.2. Locality-enhanced Projector
3.2.1 Motivation
프로젝터 설계 시 가장 중요한 요소는 생성되는 시각적 토큰의 수를 결정하는 유연성입니다. 이전에 언급된 바와 같이, 프로젝터에 의해 생성된 시각적 토큰의 수는 MLLM의 전체 효율성과 계산량을 결정합니다. 다수 또는 큰 이미지를 처리하는 시나리오를 고려할 때, 시각적 토큰 수를 줄임으로써 효율성을 높이는 것은 확장성을 위해 매우 중요합니다. 이러한 요구로 인해 최근 MLLM에서는 선형 프로젝터보다 리샘플러와 Q-포머와 같은 추상화 도구가 선호됩니다.
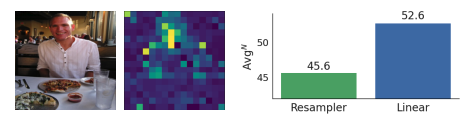
리샘플러는 선형 프로젝터에 비해 공간적 이해 작업을 수행하는 데 어려움이 있음을 관찰했습니다. 선형 프로젝터는 일대일 투영을 통해 시각적 특징의 모든 지역적 맥락을 손실 없이 유지하는 반면, 리샘플러는 몇몇 지역(예: 사람)에서 주로 정보를 요약하며, 일부 지역적 세부 사항(예: 식사, 컵, 배경의 사람들)을 간과할 수 있습니다. 이 두 모델 간의 지역적 맥락 유지 차이가 공간적 이해 성능에 큰 영향을 미쳤다고 봅니다.
시각적 토큰 수에 대한 유연성을 제공하고 지역적 맥락을 효과적으로 보존하는 두 가지 새로운 시각 프로젝터인 C-Abstractor와 D-Abstractor를 제안합니다. 이 새로운 프로젝터들은 추상화를 통한 계산 효율성과 지역적 특징 보존을 동시에 개선하여, 복잡한 시각 정보 처리에서 MLLM의 전체 성능을 향상시킬 뿐만 아니라 LLM의 이후 응답 생성 단계에서의 계산 효율성도 높입니다
3.2.1 Architecture
C-Abstractor: 컨볼루션은 지역적 맥락 모델링에서 가장 성공적인 구조로, 따라서 Convolutional Abstractor인 C-Abstractor를 효과적인 지역적 맥락 모델링을 위해 설계했습니다. 이 설계는 시각적 특징을 임의의 제곱 수의 시각적 토큰으로 추상화하고, 심지어 원래 시각적 특징 수보다 더 많은 시각적 토큰으로 투영할 수 있게 합니다.
D-Abstractor: 컨볼루션은 지역적 맥락 모델링에 성공적이지만, 지역성에 대한 과도한 엄격한 선입견을 도입한다는 비판도 있습니다. 따라서 Deformable attention 기반의 D-Abstractor를 제안합니다. 이는 추상화하는 동안 리샘플러의 지역 인식을 향상시키면서 그 유연성을 유지합니다. 변형 가능한 어텐션은 지역적 맥락을 보존하는 데 유리하며, 각 학습 가능한 쿼리는 참조점과 샘플링 오프셋을 사용하여 2-D 좌표 기반 샘플링 과정을 통해 시각적 특징을 수집합니다.
MLLM의 복잡한 시각 정보 처리 능력을 향상시키고, LLM의 응답 생성 단계에서의 계산 효율성을 높이는 것을 목표로 합니다
3.3. Training
지역성 강화 추상화기의 훈련
비전인코더와 LLM 을 동결하고, 제안된 지역성 강화 추상화를 훈련하는데 중점을 둡니다.

프로젝터와 LLM 의 공동 훈련
Pre-training for vision-language alignment.
사전 훈련의 목적은 비전 인코더와 LLM 사이의 연결을 구축하는 새로운 시각 프로젝터를 학습하는 것입니다. 이미지-텍스트 데이터(예: BlipCapFilt , COYO 를 사용하여, MLLM이 시각적 단서가 텍스트 설명과 어떻게 정렬되는지에 대한 미묘한 이해를 개발할 수 있게 합니다.
Visual instruction tuning.
프로젝터와 LLM을 공동으로 훈련하여 지시를 따르는 능력을 강화하고 더 깊은 시각적 이해를 달성합니다. 이를 위해 GPT-지원 지시 따르기 데이터셋인 LLaVA ]와 ShareGPT 를 사용합니다. 또한, 시각적 이해를 강화하기 위해 테이블 2에 나열된 다양한 기존 데이터셋을 '인스트럭션화'합니다. 구체적으로는 다음과 같은 접근 방법을 포함합니다.

데이터 셋 관련해서 참조가 많아서 이 부분은 관심 있으신분은 직접 들어가셔서 읽어보시는것을 추천드립니다.
4. Hidden Recipe for Visual Instruction Tuning
Dataset combination. (데이터셋 결합)
다양한 크기의 데이터셋을 사용할 때, 적절한 균형을 맞추는 것이 중요합니다. 이를 위해, 저자들은 다섯 가지 다른 균형 전략을 비교합니다: 1) 데이터셋 당 균일 샘플링, 2) 작업 당 균일 샘플링, 3) 샘플 당 균일 샘플링(최대 크기를 100k로 제한), 4) 데이터셋 당 경험적으로 조정된 균형 전략입니다.
Dataset balancing. (데이터셋 균형)
기존 데이터셋을 지시 형식으로 변환하는 데 사용되는 사전 정의된 템플릿의 적절한 세분성은 아직 확립되지 않았습니다. 이를 조사하기 위해, 저자들은 두 가지 서로 다른 템플릿 세분성 접근 방식을 비교합니다: 1) 세분화된 템플릿 사용, 2) 동일 작업 범주 내의 데이터셋에 공유 템플릿 적용입니다.
Template granularity. (템플릿 다양성)
GPT 지원 대화 데이터셋의 등장 전에는 다양한 사전 정의된 템플릿을 사용하여 템플릿 다양성을 확보하는 것이 중요했습니다. 그러나 GPT 지원 데이터셋의 도입으로 템플릿 다양성에 대한 강조가 줄어들었습니다. 저자들은 세 가지 다른 접근 방식을 비교하여 이를 조사합니다: 1) 단일 템플릿 사용, 2) 다중 템플릿 사용, 3) 다중 템플릿과 입력 반전 기법 사용입니다.
Multi-turn template. (멀티턴 템플릿)
기존 데이터셋을 활용할 때, 하나의 이미지에 대해 여러 입력-대상 쌍이 존재하는 것이 일반적입니다. 멀티턴 전략은 이러한 쌍들을 하나의 대화식 멀티턴 예제로 통합합니다. 이 접근법은 응답을 찾는 단순한 방법을 장려할 수 있으므로, 의미적으로 중복된 입력-대상 쌍을 제거하는 추가적인 중복 제거 전략을 도입합니다.
5. Experiments
5.1. Evaluation Setting
Benchmarks.
MME는 이진 예/아니오 질문을 사용하여 인지 이해와 시각적 추론을 평가하고, MMBench와 SEED-Bench는 다중 선택 질문을 사용합니다. 각각 MME의 인지 작업(MMEP), MMBench-dev(MMB), SEEDBench 이미지 전용(SEEDI) 분할을 사용합니다. MME에서 인지 작업에 중점을 둔 이유는 부록 F에 설명되어 있습니다. 반면에, LLaVA-Bench (In-the-Wild), LLaVAW는 GPT-4를 활용하여 MLLM의 기술적인 반응을 평가하고, 모델의 자연어 생성 및 인간 선호도에 대한 종합적인 관점을 제공합니다.
Metrics.
개별 벤치마크에 대해 공식 구현을 사용하여 계산된 공식 측정 지표를 기본적으로 보고합니다. 또한, 벤치마크 간에 정규화된 평균 AvgN을 보고합니다. AvgN은 각각의 최대 점수에 의해 정규화된 점수의 평균으로 정의됩니다.
5.2. Implementation Details
7B와 13B 크기의 Vicuna-v1.5 언어 모델과 사전 훈련된 CLIP ViT-L/14 비전 인코더를 활용합니다. 특히, CLIP의 두 번째 마지막 레이어를 사용하며, 이미지 특정 토큰은 사용하지 않습니다. 전체 LLM을 훈련시키며, 200k 사전 훈련 및 10k 인스트럭션 튜닝을 포함하는 긴 훈련 스케줄과 50k 사전 훈련 및 4k 인스트럭션 튜닝을 포함하는 짧은 훈련 스케줄을 사용합니다. 자세한 정보는 부록 C에 있습니다. 이러한 구현은 MLLM의 효과적인 훈련과 성능 평가를 위한 기술적 전략을 제시합니다.
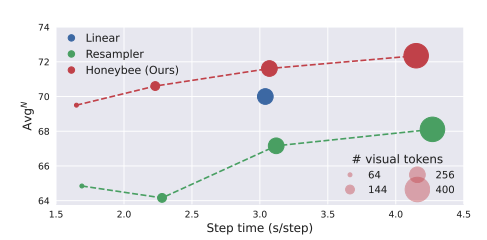
5.3. Analysis on Locality-Enhanced Projector
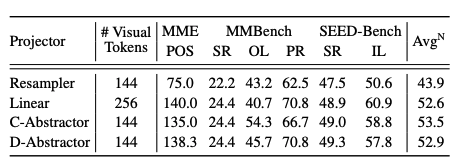
지역성 강화 프로젝터가 공간 이해 능력을 크게 향상시키며, 특히 리샘플러에 비해 뛰어난 성능을 보임을 보여줍니다.
5.4. Hidden Recipe for Visual Instruction Tuning
Dataset combination.
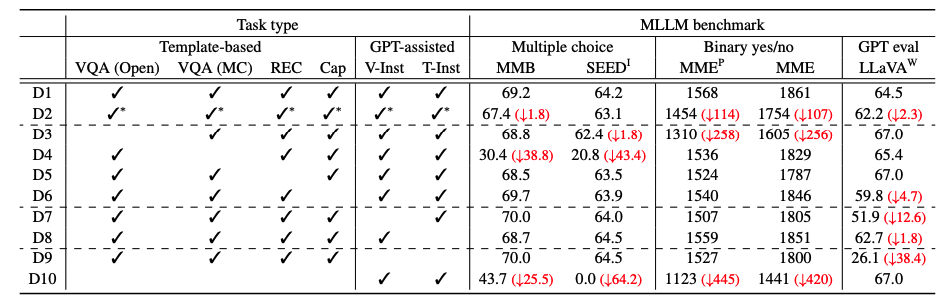
특정 작업 유형별 단일 데이터셋으로 훈련하여 데이터셋 다양성의 중요성을 밝혀냈습니다. 오픈엔드 VQA 작업의 제외가 벤치마크 점수에 큰 영향을 미치며, 다양한 멀티모달 지식이 MLLM 지식을 풍부하게 한다는 것을 시사합니다.
Dataset balancing.
수작업 데이터셋 균형 조정의 필요성: 이전 연구들에서 언급된 데이터셋 균형 조정의 중요성을 다룹니다. 균형 조정 시험에 대해 연구합니다.
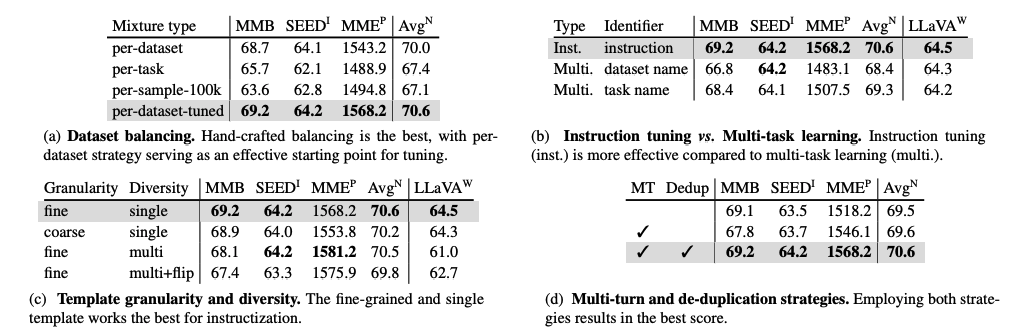
- 5a: 수작업으로 조정된 데이터셋별 균형 전략이 효과적임을 보여줍니다. 수작업 없이도 데이터셋별 전략이 신뢰할 수 있는 대안이 될 수 있습니다.
- 5b: 인스트럭션 튜닝이 멀티태스크 학습보다 효과적임을 나타냅니다. 템플릿 기반 포맷팅을 사용하는 인스트럭션 튜닝이 단순 식별자를 사용하는 멀티태스크 학습보다 우수한 결과를 보입니다.
- 5c: 세분화된 단일 템플릿이 가장 좋은 결과를 보여줍니다. 세분화된 템플릿과 다중 템플릿, 그리고 다중 템플릿에 입력 반전을 추가한 세 가지 시나리오를 비교한 결과, 세분화된 단일 템플릿이 가장 효과적입니다.
- 5d: 멀티턴 및 중복 제거 전략을 모두 사용할 때 가장 좋은 점수를 얻습니다. 이는 각 예시에서 의미론적으로 중복되는 쌍을 제거하는 것이 단순한 답변 찾기를 완화하는 데 효과적임을 시사합니다.
해상도와 M은 각각 이미지 해상도와 비주얼 토큰 수를 나타냅니다, 가장 좋은 결과와 두 번째로 좋은 결과를 굵은 글씨와 밑줄로 강조 했다고 합니다.
5.5. Putting It Altogether
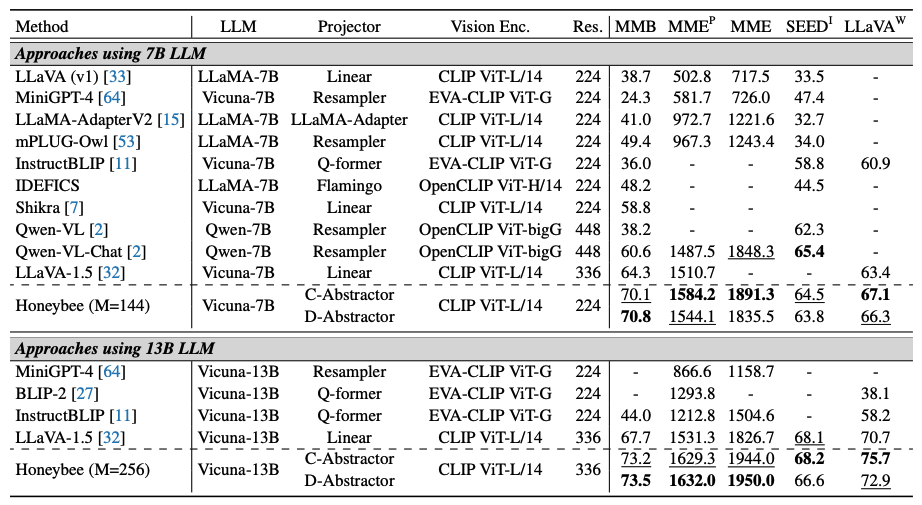
- Honeybee의 성능: Honeybee는 SEEDI를 제외한 모든 벤치마크에서 비교 가능한 7B 규모의 MLLMs를 능가합니다. 경쟁 모델들인 Qwen-VL [2]과 LLaVA-1.5 [32]는 더 큰 비전 인코더(예: Qwen-VL의 ViT-bigG) 또는 더 큰 이미지(448 및 336)와 증가된 시각적 토큰(256 및 576)을 사용하는 반면, Honeybee는 ViT-L/14를 224 해상도와 144 시각적 토큰으로 사용합니다.
- SEEDI의 세부 시각 이해: SEEDI의 세부적인 시각 이해에 초점을 맞춘다면(부록 F 참조), 더 큰 이미지 또는 더 많은 시각적 토큰이 유리할 수 있습니다. 시각적 토큰을 144에서 256으로 늘릴 경우, Honeybee는 7B 규모 LLM에서 SEEDI에서 최고 점수(65.5)를 달성합니다(표 7 참조).
- 13B 규모 LLM에서의 Honeybee: 13B 규모 LLM을 사용할 때, Honeybee는 모든 벤치마크에서 이전 방법들을 능가합니다.
5.6. Additional Results
한계를 도전하고 7B , 13B 모델에서의 성능과 효율성 균형을 위해 사용된 시각적 토큰 수에 대해 논의
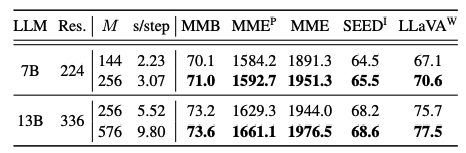
- 시각적 토큰 수(M) 증가의 효과: 시각적 토큰 수를 증가시키면 일관되게 성능이 향상됩니다. Honeybee에서 선형 프로젝터와 M을 맞추는 실험(표)는 효율성을 희생하면서 성능을 향상시킵니다.
- 과학 QA 평가 결과: ScienceQA [38] 평가 결과는 부록 G.3에 제시되어 있습니다. 특별한 세부 튜닝 없이도, 범용 Honeybee는 최고의 성능(94.39)을 달성하여, 전문가 모델들인 MM-CoT (91.68) 및 LLaVA+GPT-4 (92.53)를 능가합니다.
6. Conclusion
비주얼 인스트럭션 튜닝의 출현은 멀티모달 대규모 언어 모델(MLLM) 분야에 눈에 띄는 진보를 가져왔습니다. 그럼에도 불구하고, 프로젝터 디자인과 다면적 데이터 처리에 대한 접근 방식은 여전히 미개척 영역이거나 명확하지 않습니다. 이러한 격차를 해소하기 위해, 프로젝터 속성인 지역성 보존을 식별하고, 성능과 효율성 사이의 바람직한 균형을 제공하는 지역성 강화 프로젝터를 제안합니다. 또한, 다면적인 인스트럭션 데이터를 다루는 데 있어 개별 설계 선택의 영향을 파악하기 위한 광범위한 실험을 제공하여, 고성능 MLLM 개발을 위한 숨겨진 레시피를 밝힙니다. Honeybee는 다양한 벤치마크에서 이전의 최신 방법들을 현저하게 능가합니다.



