OpenLLM leaderboad에 참여하기 위해, 가장 먼저 Llama2 파인튜닝 코드를 분석하면서 이해해보려고합니다.
https://colab.research.google.com/drive/1PEQyJO1-f6j0S_XJ8DV50NkpzasXkrzd
Fine-tune Llama 2 in Google Colab.ipynb
Colaboratory notebook
colab.research.google.com
위 코드를 보고 따라서 진행해보았습니다.
1. 파이썬 라이브러리 설치
!pip install -q accelerate==0.21.0 peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7- accelerate==0.21.0: Hugging Face의 accelerate 라이브러리는 딥러닝 모델의 트레이닝을 가속화하기 위해 사용. 이 라이브러리를 사용하면 CPU, GPU, 혹은 TPU에서 모델을 더 빠르게 트레이닝할 수 있습니다.
- peft==0.4.0: 퍼포먼스 튜닝과 관련된 기능을 제공
- bitsandbytes==0.40.2: 이 라이브러리는 특히 딥러닝 모델의 트레이닝에서 메모리 사용량을 줄이는데 도움을 줍니다. 이를 통해 보다 효율적인 메모리 관리가 가능하며, 이는 특히 대규모 모델을 다룰 때 중요합니다.
- transformers==4.31.0: Hugging Face의 transformers 라이브러리는 다양한 사전 트레이닝된 모델들을 제공합니다. 이들 모델은 자연어 처리(NLP) 작업에 널리 사용되며, 파인튜닝을 위한 기본 구조를 제공합니다.
- trl==0.4.7: trl은 Text Reinforcement Learning의 약자로, 이 라이브러리는 텍스트 기반 강화학습을 위한 도구들을 제공합니다. 이는 모델의 성능을 최적화하고, 특정 작업에 맞게 모델을 조정하는 데 사용됩니다.
2. 파이썬 라이브러리 Import
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig, PeftModel
from trl import SFTTrainer- from transformers import (...): Hugging Face의 transformers 라이브러리에서 다양한 클래스와 함수들을 임포트합니다. 이들은 주로 사전 트레이닝된 모델을 불러오고, 토크나이저를 사용하고, 트레이닝 설정을 정의하는 데 사용됩니다.
- from peft import LoraConfig, PeftModel: peft 라이브러리에서 LoraConfig와 PeftModel을 임포트합니다. 이들은 모델의 퍼포먼스를 향상시키는데 사용되는 설정과 모델 구조를 제공합니다.
- LoRA : Low-Rank Adaptation
- PEFT : Parameter-Efficient Fine-Tuning
- from trl import SFTTrainer: trl 라이브러리에서 SFTTrainer를 임포트합니다. 이 클래스는 텍스트 강화학습을 위한 트레이너로, 모델을 트레이닝하고 최적화하는 데 사용됩니다
3. 모델 및 데이터셋 설정
# The model that you want to train from the Hugging Face hub
model_name = "NousResearch/Llama-2-7b-chat-hf"
# The instruction dataset to use
dataset_name = "mlabonne/guanaco-llama2-1k"
# Fine-tuned model name
new_model = "llama-2-7b-miniguanaco"- 모델과 데이터셋을 Huggingface로부터 Load하고, Fine-tuning한 모델을 저장할 이름을 설정합니다.
4. QLoRA 파라미터 설정
# LoRA attention dimension
lora_r = 64
# Alpha parameter for LoRA scaling
lora_alpha = 16
# Dropout probability for LoRA layers
lora_dropout = 0.1- QLoRA :Quantized Low-Ranking Adaptation, LoRA에 양자화를 적용한 형태. https://arxiv.org/abs/2305.14314
- lora_r: LoRA(Linear+Rectified Linear Unit Attention)의 차원을 정의
- lora_alpha: LoRA 스케일링을 위한 알파 매개변수
- lora_dropout: LoRA 레이어에서 사용할 드롭아웃 확률을 의미.
QLoRA: Efficient Finetuning of Quantized LLMs
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quan
arxiv.org
5. Bitsandbytes 파라미터 설정
# Activate 4-bit precision base model loading
use_4bit = True
# Compute dtype for 4-bit base models
bnb_4bit_compute_dtype = "float16"
# Quantization type (fp4 or nf4)
bnb_4bit_quant_type = "nf4"
# Activate nested quantization for 4-bit base models (double quantization)
use_nested_quant = False- bitsandbytes는 메모리 사용량을 줄이고 효율적인 트레이닝을 가능하게 하는 경량 wrapper 라이브러리. 여기서는 QLora기술과 통합되어 사용
- use_4bit: 4비트 정밀도의 모델을 사용할지 여부를 결정합니다. 여기서는 True로 설정되어 있어 활성화됩니다.
- bnb_4bit_compute_dtype: 4비트 모델을 위한 계산 데이터 타입입니다. 여기서는 "float16"으로 설정되어 있습니다.
- bnb_4bit_quant_type: 양자화 유형을 정의합니다. "nf4"로 설정되어 있습니다.
- use_nested_quant: 4비트 모델에 대한 중첩 양자화(이중 양자화)를 사용할지 여부입니다. False로 설정되어 비활성화됩니다.
6. TrainingArguments 파라미터 설정
- 저장 경로, epoch수, batchsize 등 트레이닝 과정 제어 파라미터 설정
# Output directory where the model predictions and checkpoints will be stored
output_dir = "./results"
# Number of training epochs
num_train_epochs = 1
# Enable fp16/bf16 training (set bf16 to True with an A100)
fp16 = False
bf16 = False
# Batch size per GPU for training
per_device_train_batch_size = 4
# Batch size per GPU for evaluation
per_device_eval_batch_size = 4
# Number of update steps to accumulate the gradients for
gradient_accumulation_steps = 1
# Enable gradient checkpointing
gradient_checkpointing = True
# Maximum gradient normal (gradient clipping)
max_grad_norm = 0.3
# Initial learning rate (AdamW optimizer)
learning_rate = 2e-4
# Weight decay to apply to all layers except bias/LayerNorm weights
weight_decay = 0.001
# Optimizer to use
optim = "paged_adamw_32bit"
# Learning rate schedule
lr_scheduler_type = "cosine"
# Number of training steps (overrides num_train_epochs)
max_steps = -1
# Ratio of steps for a linear warmup (from 0 to learning rate)
warmup_ratio = 0.03
# Group sequences into batches with same length
# Saves memory and speeds up training considerably
group_by_length = True
# Save checkpoint every X updates steps
save_steps = 0
# Log every X updates steps
logging_steps = 257. SFT(Supervised Fine-tuning Trainer) 파라미터 설정
- https://huggingface.co/docs/trl/main/en/sft_trainer
- max_seq_length: 모델에 입력되는 시퀀스의 최대 길이입니다. 여기서는 None으로 설정되어 기본값을 사용합니다.
- packing: 여러 짧은 예제들을 하나의 입력으로 묶어 효율성을 높일지 여부입니다. False로 설정되어 비활성화되어 있습니다.
- device_map: 모델이 어떤 GPU 장치에 로드될지를 지정합니다. 여기서는 모든 모델이 GPU 0에 로드되도록 설정되어 있습니다.
Supervised Fine-tuning Trainer
huggingface.co
# Maximum sequence length to use
max_seq_length = None
# Pack multiple short examples in the same input sequence to increase efficiency
packing = False
# Load the entire model on the GPU 0
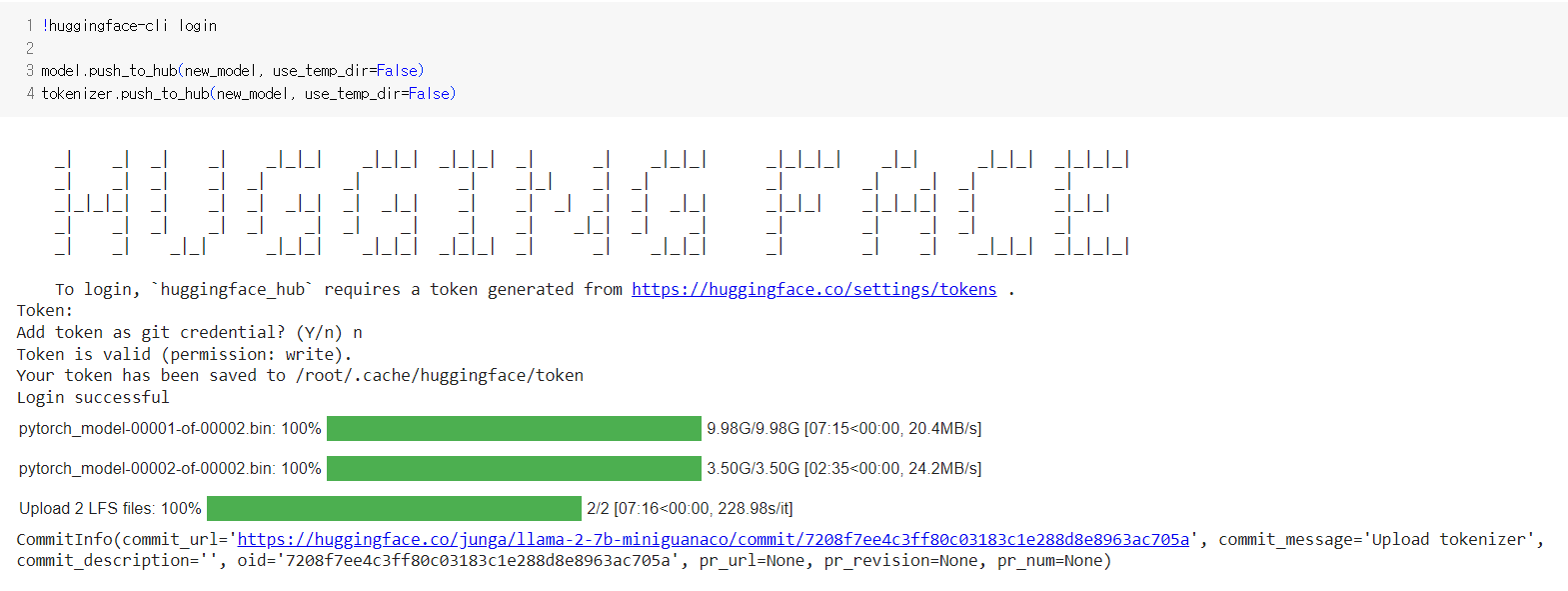
device_map = {"": 0}다음 글에 이어서 데이터셋 로딩 및 모델 설정, 트레이닝 파라미터 설정, 모델 트레이닝 및 저장 등 나머지 코드에 대해서 분석하겠습니다.
다음 글 : https://wiz-tech.tistory.com/79
[Fine-tuning] Llama2 파인튜닝 코드해석 2탄
https://wiz-tech.tistory.com/78에 이어서 진행해보겠습니다. [Fine-tuning] Llama2 파인튜닝 코드해석 import os import torch from datasets import load_dataset from transformers import ( AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfi
wiz-tech.tistory.com
'AI > Study' 카테고리의 다른 글
| AI 취업 시장의 변화 (3) | 2024.02.13 |
|---|---|
| [Fine-tuning] Llama2 파인튜닝 코드해석 2탄 (7) | 2024.01.30 |
| [머신러닝] XGBoost 알고리즘이란? (4) | 2024.01.22 |
| [LangChain] LangChain이란 무엇인가? - (1) (1) | 2024.01.10 |
| Git 커밋의 기술: 신입 개발자(나)를 위한 가이드 (0) | 2024.01.10 |



